

爬虫

发布于 2022-01-29
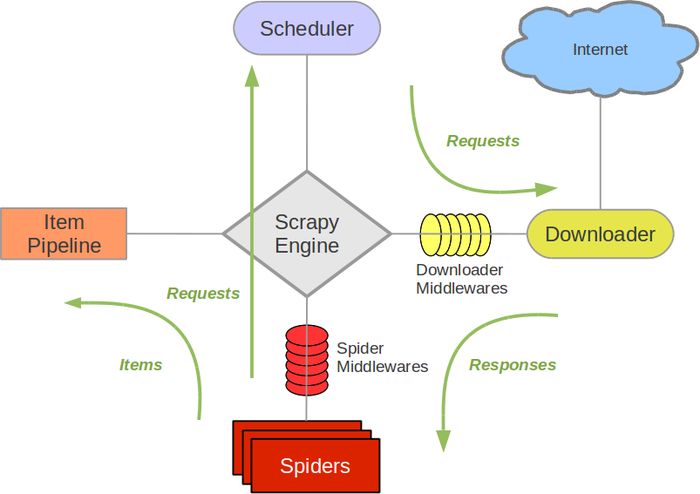
记录第一次对网易云音乐评论的爬取——牛刀小试(1)
首先声明:本爬虫仅供学习交流使用,没有任何商业用途,如有侵犯行为,请联系作者删除! 由于毕业设计的内容与网易云音乐相关,需要得到一 …

发布于 2020-07-20
使用BeautifulSoup进行数据解析
Beautiful soup思维导图:点击这里 啥是Beautiful soup,美丽的汤?? 和lxml一样,Beautiful …
发布于 2020-07-20
request+xpath+lxml实战
使用爬虫爬取页面步骤: step1:使用urllib库或者request库得到页面,一般用request,比较方便 step2:我 …
发布于 2020-07-19
使用XPath+lxml进行数据解析
当我们使用urllib库或者request库获取到了页面html文件后,我们需要从这些html中获取到我们所需要的数据,这就需要使 …
发布于 2020-07-13
爬虫——Http协议和Chrome浏览器
Http和Https HTTP协议:全称是HyperText Transfer Protocol,中文意思是超文本传输协议,是一种 …