

Beautiful soup思维导图:点击这里
啥是Beautiful soup,美丽的汤??
和lxml一样,Beautiful Soup也是一个HTML / XML的解析器,主要的功能也是如何解析和提取HTML / XML数据。
但是lxml只是局部遍历,而Beautiful Soup是基于HTML DOM(文档对象模型)的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于LXML。
BeautifulSoup用来解析HTML比较简单,API非常人性化,支持CSS选择器,Python的标准库中的HTML解析器,也支持lxml的XML解析器。Beautiful Soup 3目前已经停止开发,推荐现在的项目使用Beautiful Soup 4。
安装和文档
- 安装:pip install bs4
- 文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
几大解析工具对比
| 工具 | 解析速度 | 使用难度 |
| lxml | 快 | 容易 |
| beautiful soup | 慢 | 最容易 |
| 正则表达式 | 最快 | 最难 |
四个常用对象
beautiful soup将复杂的HTML文档转换成一个树形结构,每个节点都是python对象,所有的对象可以归纳为以下四种:
- BeautifulSoup
- Tag
- NavigableStringl
- Comment
BeautifulSoup
创建一个beautiful对象:soup = BeautifulSoup(html, 'lxm')
Beautiful Soup支持python标准库中的HTML解析器,还支持一些第三方的解析器,在我们使用BeautifulSoup的时候,选择怎样的解析器是至关重要的,使用不同的解析器有可能会出现不同的结果,下表列出了主要的解析器,以及他们的优缺点。
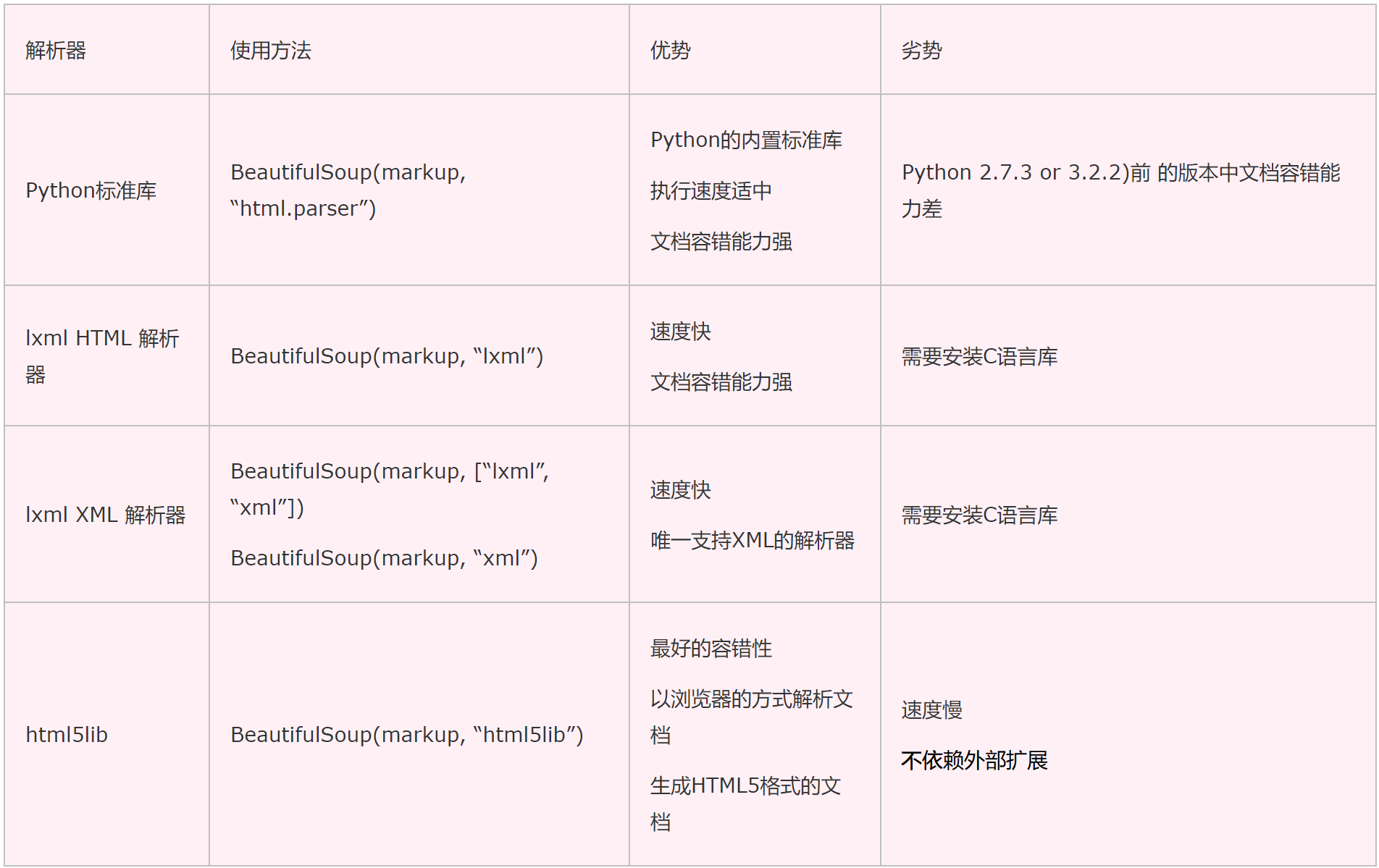
BeautifulSoup 这个类的父类是 Tag,因此 Tag 里面能用的方法 BeautifulSoup 类都能 用。
这里有一个神操作,有些网站的设计者写的 html 代码不规范,当爬取表格(table) 的内容时,发现用 xpath helper 获取正常,但是使用的python 程序却解析不到,出现这种原因是因为浏览器会对html文本进行一定的规范化,我们要选择html5lib解析器, 它会对代码进行优化,如果要将优化后的代码在其他爬虫包使用,可以使用以下函数。
from bs4 import BeautifulSoup
def prettify_html(html_text) :
soup = BeautifulSoup(html_text, 'html5lib')
return soup.prettify()Tag
顾名思义,就是html中的一个个标签,Tag有两个属性:name和attributes:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>', 'lxml')
tag = soup.b
print(tag.name) #每个tag都有自己的名字,通过.name来获取
print(tag['class']) #tag <b class = "boldest">有一个“class”的属性,值为“boldest”
print(tag.attrs) #也可以直接点取属性,如:.attrs
NavigableString
如果我们拿到标签后,还想获取标签中的内容,那么可以通过tag.string获取标签中的文字,示例代码:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>', 'lxml')
tag = soup.b
print(tag.string)
print(type(tag.string))
Comment
可以获取标签内的注释部分(比较鸡肋),示例程序:
from bs4 import BeautifulSoup
markup = "<b><!--hello world--></b>"
soup = BeautifulSoup(markup, 'lxml')
comment = soup.b.string
print(comment)
print(type(comment))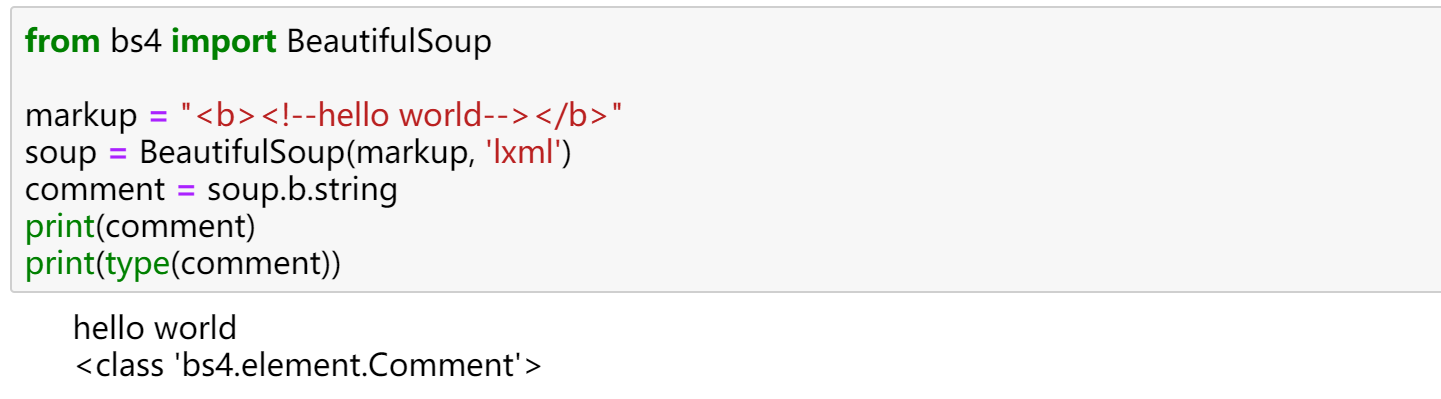
文档搜索树
find和find_all
搜索文档树,一般用得比较多的就是两个方法,一个是 find,一个是 find_all。find 方法是找到第一个满足条件的标签后就立即返回,只返回一个元素。find_all 方法是把所有满足条件的标签都选到,然后返回回去。
注意:
- soup_find_all 返回的是一个类似于列表的的东西,因此我们可以通过取下标的方式 得到里面的元素,里面每个元素都是 Tag
- find_all 里面有一个参数,叫做 Limits,这样只会找到前几个元素
- find 是只找一个符合要求的元素
假设我们有如下源码和如下需求:
<table class="tablelist" cellpadding="0" cellspacing="0">
<tbody>
<tr class="h">
<td class="l" width="374">职位名称</td>
<td>职位类别</td>
<td>人数</td>
<td>地点</td>
<td>发布时间</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=33824&keywords=python&tid=87&lid=2218">22989-金融云区块链高级研发工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=29938&keywords=python&tid=87&lid=2218">22989-金融云高级后台开发</a></td>
<td>技术类</td>
<td>2</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=31236&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐运营开发工程师(深圳)</a></td>
<td>技术类</td>
<td>2</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=31235&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐业务运维工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=34531&keywords=python&tid=87&lid=2218">TEG03-高级研发工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=34532&keywords=python&tid=87&lid=2218">TEG03-高级图像算法研发工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=31648&keywords=python&tid=87&lid=2218">TEG11-高级AI开发工程师(深圳)</a></td>
<td>技术类</td>
<td>4</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=32218&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=32217&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="odd">
<td class="l square"><a id="test" class="test" target='_blank' href="position_detail.php?id=34511&keywords=python&tid=87&lid=2218">SNG11-高级业务运维工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
</tbody>
</table>- 获取所有tr标签
- 获取第2个tr标签
- 获取所有class等于even的tr标签
- 将所有id等于test,class也等于test的a标签提取出来
- 获取所有a标签的href属性
- 获取所有的职位信息(纯文本)
由于bs4不支持本地读取html,所以每次都要放html有点麻烦,这里为了简单起见,我只任务一放了html,后面的读者自行加上即可
#获取所有tr标签
from bs4 import BeautifulSoup
html = """
<table class="tablelist" cellpadding="0" cellspacing="0">
<tbody>
<tr class="h">
<td class="l" width="374">职位名称</td>
<td>职位类别</td>
<td>人数</td>
<td>地点</td>
<td>发布时间</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=33824&keywords=python&tid=87&lid=2218">22989-金融云区块链高级研发工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=29938&keywords=python&tid=87&lid=2218">22989-金融云高级后台开发</a></td>
<td>技术类</td>
<td>2</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=31236&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐运营开发工程师(深圳)</a></td>
<td>技术类</td>
<td>2</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=31235&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐业务运维工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=34531&keywords=python&tid=87&lid=2218">TEG03-高级研发工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=34532&keywords=python&tid=87&lid=2218">TEG03-高级图像算法研发工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=31648&keywords=python&tid=87&lid=2218">TEG11-高级AI开发工程师(深圳)</a></td>
<td>技术类</td>
<td>4</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=32218&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=32217&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="odd">
<td class="l square"><a class = 'test' id = 'test' target="_blank" href="position_detail.php?id=34511&keywords=python&tid=87&lid=2218">SNG11-高级业务运维工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
</tbody>
</table>
"""
soup = BeautifulSoup(html, 'lxml')
trs = soup.find_all("tr")
for tr in trs:
print(tr)#获取第2个tr标签
soup = BeautifulSoup(html, 'lxml')
tr = soup.find_all("tr", limit = 2)[1] #使用limit可以限制最多取两个,下标这里是从零开始
print(tr)# 获取所有class等于even的tr标签
#写法一:
soup = BeautifulSoup(html, 'lxml')
trs = soup.find_all("tr", class_ = "even") #注意这里,由于class是python中的关键字,所以在这里选择的时候,后面要加一条下划线
for tr in trs:
print(tr)
#写法二:
soup = BeautifulSoup(html, 'lxml')
trs = soup.find_all("tr", attrs = {'class':"even"})
for tr in trs:
print(tr)#将所有id等于test,class也等于test的a标签提取出来
#写法一:
soup = BeautifulSoup(html, 'lxml')
aList = soup.find_all("a", id = 'test', class_ = 'test')
for a in aList:
print(a)
写法二:
soup = BeautifulSoup(html, 'lxml')
aList = soup.find_all("a", attrs = {"id" : "test", "class" : "test"})
for a in aList:
print(a)#获取所有a标签的href属性
#写法一,直接用中括号选择属性
soup = BeautifulSoup(html, 'lxml')
aList = soup.find_all("a")
for a in aList:
print(a['href'])
#写法二,用attrs方法
soup = BeautifulSoup(html, 'lxml')
aList = soup.find_all("a")
for a in aList:
print(a.attrs['href'])#获取所有的职位信息(纯文本)
#方法一:麻烦
soup = BeautifulSoup(html, 'lxml')
trs = soup.find_all('tr')[1:] # 切片去表头
positions = []
for tr in trs:
td = tr.find_all('td')
position = {}
position['职位名称'] = td[0].string # 直接string可以得到内容
position['类别'] = td[1].string
position['人数'] = td[2].string
position['地点'] = td[3].string
position['发布时间'] = td[4].string
positions.append(position)
for position in positions:
print(position)
#获取所有的职位信息(纯文本)
#方法二:有换行符
soup = BeautifulSoup(html, 'lxml')
infos = {}
trs = soup.find_all("tr")
for tr in trs:
infos = list (tr.strings) #直接拿文字,strings返回一个生成器,可以转换成列表
,strings后面有介绍
print(infos) 
但是有问题,因为有很多换行符也给我们保存下来了,这个时候不要慌,要相信python,没错,python已经考虑到了这个问题,于是stripped_strings来了
#获取所有的职位信息(纯文本)
#方法三:清爽
soup = BeautifulSoup(html, 'lxml')
info = {}
infos = []
trs = soup.find_all("tr")
for tr in trs:
position = list(tr.stripped_strings) #因为得到的是一个生成器,所以也需要转换成列表
info['title'] = position[0]
info['kind'] = position[1]
info['nums'] = position[2]
info['place'] = position[3]
info['pubtime'] = position[4]
infos.append(info)
print(infos)
总结:
- find_all的使用:
- 在提取标签的时候,第一个参数是标签的名字。然后如果在提取标签的时候想要使用标签属性进行过滤,那么可以在这个方法中通过关键字参数的形式,将属性的名字以及对应的值传进去。或者是使用
attrs属性,将所有的属性以及对应的值放在一个字典中传给attrs属性 - 有些时候,在提取标签的时候,不想提取那么多,那么可以使用
limit参数。限制提取多少个。
- 在提取标签的时候,第一个参数是标签的名字。然后如果在提取标签的时候想要使用标签属性进行过滤,那么可以在这个方法中通过关键字参数的形式,将属性的名字以及对应的值传进去。或者是使用
- find与find_all的区别
- find:找到第一个满足条件的标签就返回。就是只会返回一个元素。
- find_all:将所有满足条件的标签都返回。会返回很多标签(以列表的形式)。
- 使用find和find_all的过滤条件:
- 关键字参数:将属性的名字作为关键字参数的名字,以及属性的值作为关键字参数的值进行过滤。
- attrs参数:将属性条件放到一个字典中,传给attrs参数。
- string和strings、stripped_strings属性以及get_text方法:
- string:获取某个标签下的非标签字符串。返回来的是个字符串。如果这个标签下有多行字符,那么就不能获取到了
- strings:获取某个标签下的子孙非标签字符串。返回来的是个生成器,可转成列表
- stripped_strings:获取某个标签下的子孙非标签字符串,会去掉空白字符。返回来的是个生成器,可转成列表
- get_text:获取某个标签下的子孙非标签字符串。不是以列表的形式返回,是以普通字符串返回
CSS选择器
使用以上方法可以方便的发现元素。但有时使用css选择器的方式可以更加的方便。使用css选择器的语法,应该使用select方法。以下列出几种常用的css选择器方法
- 通过标签名来查找
- print(soup.select('a')) #找到所有的a标签,并以列表的形式返回
- 通过类名来查找:通过类名,则在类的前面加一个点,比如要查找class=sister的标签,示例代码:
- print(soup.select('.sister'))
- 通过id查找:通过id查找,则应该在id的名字前面加上一个#号:
- print(soup.select("#link1"))
- 组合查找:例如查找p标签中,id等于link1的内容,同时需要用空格分开:
- 子孙:print(soup.select("p link1"))
- 直接子标签:print(soup.select("p > #link"))
- 通过属性查找:查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。示例代码如下:
- print(soup.select('a[href = 'xxxxxxxx']'))
- 获取内容:以上的 select 方法返回的结果都是列表形式,可以遍历形式输出,然后用 get_text() 方法来获取它的内容。示例代码如下:
soup = BeautifulSoup(html, 'lxml')
print(type(soup.select('title')))
print(soup.select('title')[0].get_text())
for title in soup.select('title'):
print title.get_text()
遍历文档树
返回某个标签下的直接子元素,其中也包括字符串。他们两的区别是:contents返回来的是一个列表,children返回的是一个迭代器
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc,'lxml')
head_tag = soup.head
# 返回所有子节点的列表
print(head_tag.contents)
# 返回所有子节点的迭代器
for child in head_tag.children:
print(child)
其实我感觉遍历的原理没必要了解,毕竟python,会用就行,其他的就留给数据结构吧。
Comments NOTHING