

使用爬虫爬取页面步骤:
- step1:使用urllib库或者request库得到页面,一般用request,比较方便
- step2:我们request得到的对象进行解码处理,因为在网页和我们电脑上进行传输和存储的数据一般为bytes类型,而在pytho中对其操作则需要字符串类型
- step3:在我们要爬取的网页端检查元素,分析网页结构
- step4:使用xpath或者bs4或者正则表达式对页面进行解析(这里以xpath举例,因为后面的我还没学^_^)
- step5:将解析的结果保存就ok了
豆瓣电影
如果我们需要获得即将上市的电影的信息:
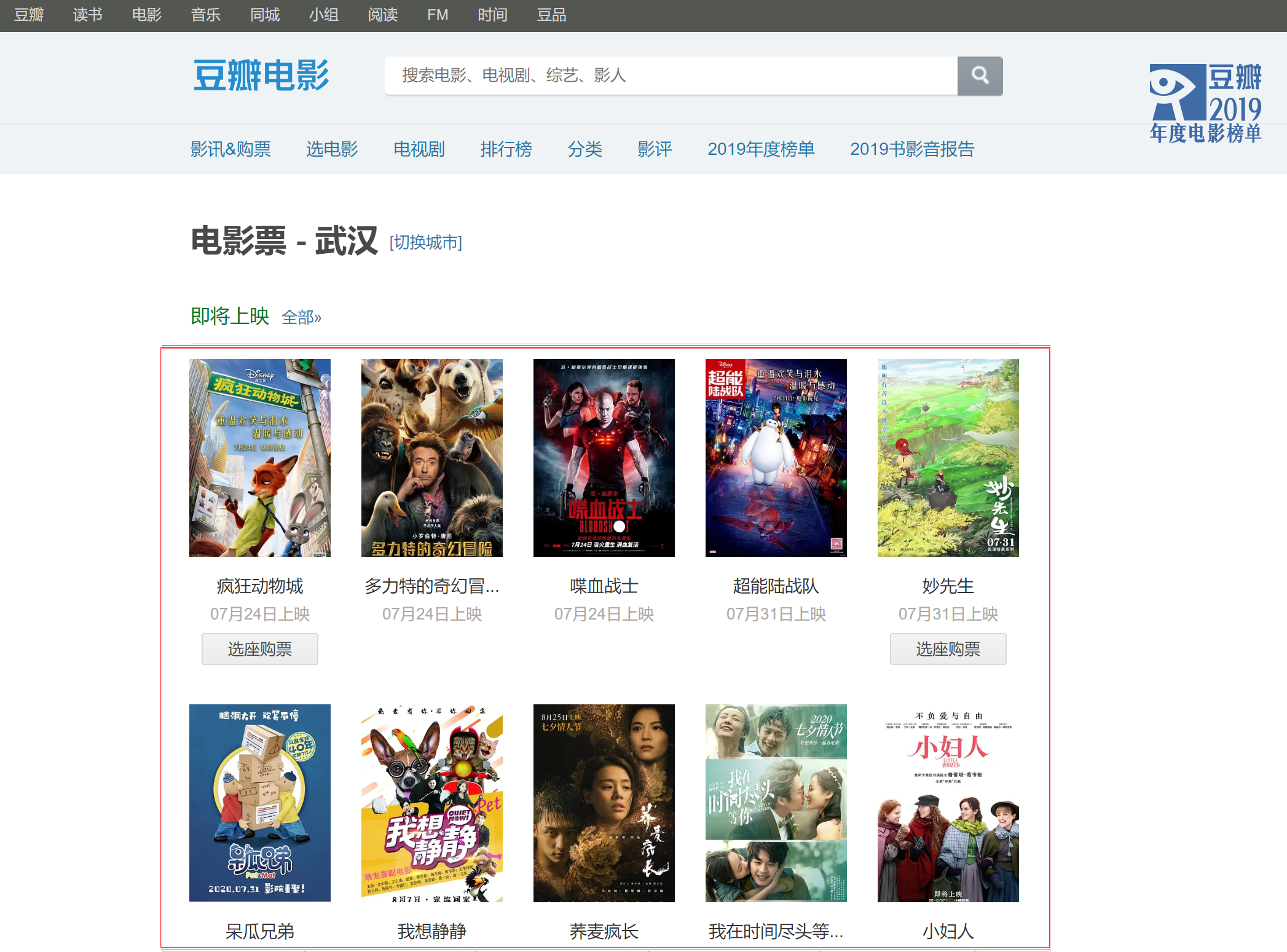
首先使用request库请求页面,然后对得到的响应进行解码处理:
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Referer' : 'https://movie.douban.com/' #如果有的话,一定要加上,反爬虫机制
}
url = 'https://movie.douban.com/cinema/nowplaying/wuhan/'
response = requests.get(url, headers = headers)
response = response.text #类型要变成text(string类型),或者content.decode('你需要的编码格式'),否则etree.HTML会出错
然后分析页面,可以发现,我们所需要的信息,都放在一个无序列表中,无序列表有一个属性:class = 'lists',我们先根据这个来定位。
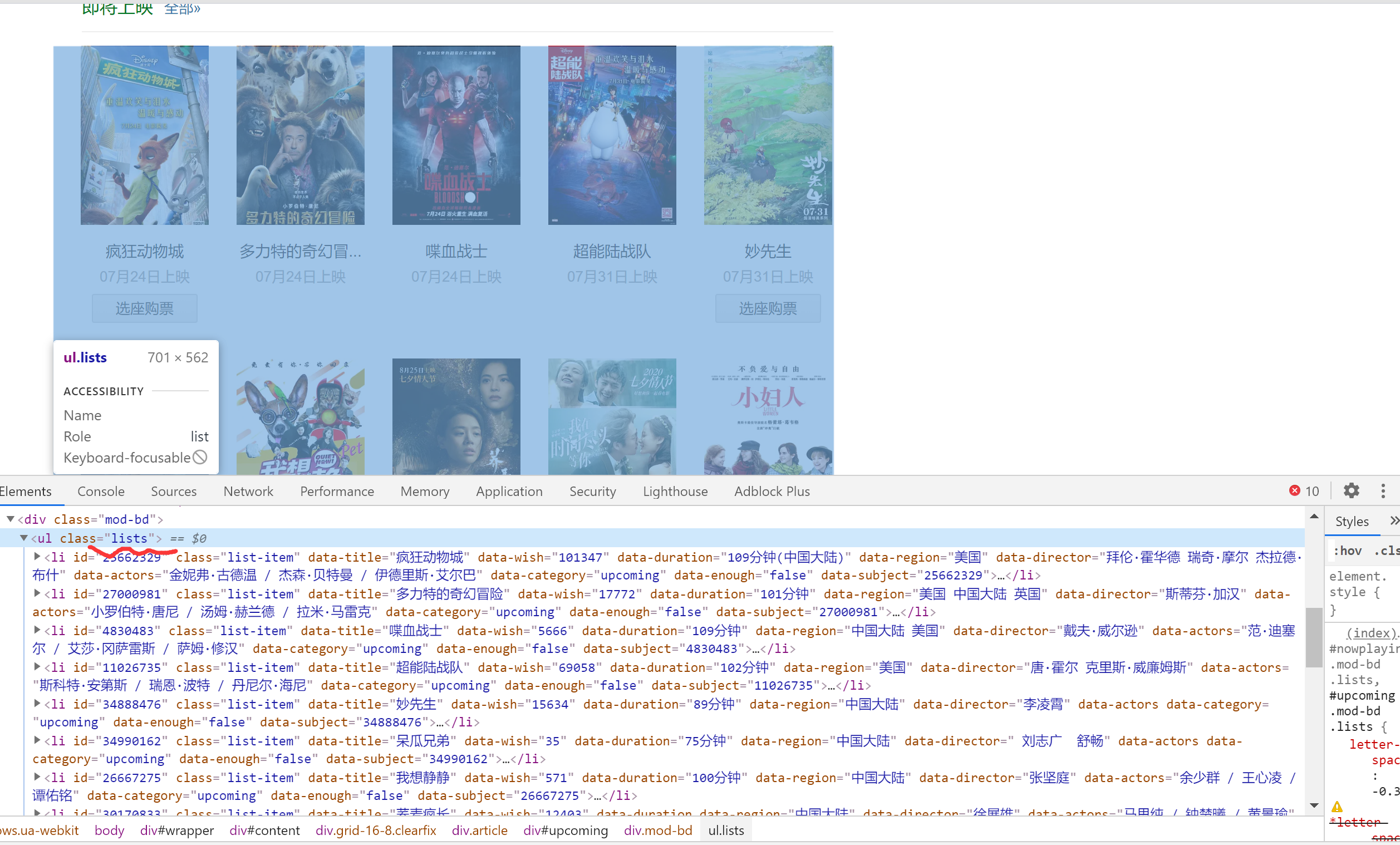
result = etree.HTML(response) #使用etree下的HTML方法构造一个htmlElement类型的元素
uls = result.xpath("//ul[@class = 'lists']")[0] #获取第一个ul中class属性值为lists的对象
lis = uls.xpath("./li") #获取其下的所有li标签,因为我们所需要的信息都保存在li标签中
现在,即将上映的电影的信息,都被保存在了lis这个列表中,我们遍历列表,然后以字典的形式存储信息

在属性中,比较特殊的是海报的封面,它并不是直接出现在li标签中,而是其下面的标签,如图:

for li in lis:
title = li.xpath("@data-title")[0] #获取li标签中,元素为data-title的西信息
duration = li.xpath("@data-duration")[0]
region = li.xpath("@data-region")[0]
director = li.xpath("@data-director")[0]
actors = li.xpath("@data-actors")[0]
pic = li.xpath(".//img/@src")[0] #由于图片比较特殊,所以与前面的不太一样
movie = {
"title" : title,
"duration" : duration,
"region" : region,
"director" : director,
"actors" : actors,
"pic" : pic
}
movies.append(movie) #保存到字典中
for movie in movies :
print(movie)
这就是爬取豆瓣电影的全部过程了,相对来说是非常简单的
全部代码:
import requests
from lxml import etree
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Referer' : 'https://movie.douban.com/' #如果有的话,一定要加上,反爬虫机制
}
url = 'https://movie.douban.com/cinema/nowplaying/wuhan/'
response = requests.get(url, headers = headers)
response = response.text #类型要变成text(string类型),否则etree.HTML会出错
result = etree.HTML(response) #使用etree下的HTML方法构造一个htmlElement类型的元素
uls = result.xpath("//ul[@class = 'lists']")[0] #获取第一个ul中class属性值为lists的对象
lis = uls.xpath("./li") #获取其下的所有li标签
movies = []
for li in lis:
title = li.xpath("@data-title")[0] #分别获取对象
duration = li.xpath("@data-duration")[0]
region = li.xpath("@data-region")[0]
director = li.xpath("@data-director")[0]
actors = li.xpath("@data-actors")[0]
pic = li.xpath(".//img/@src")[0]
movie = {
"title" : title,
"duration" : duration,
"region" : region,
"director" : director,
"actors" : actors,
"pic" : pic
}
movies.append(movie) #保存到字典中
for movie in movies :
print(movie)
执行结果:

电影天堂
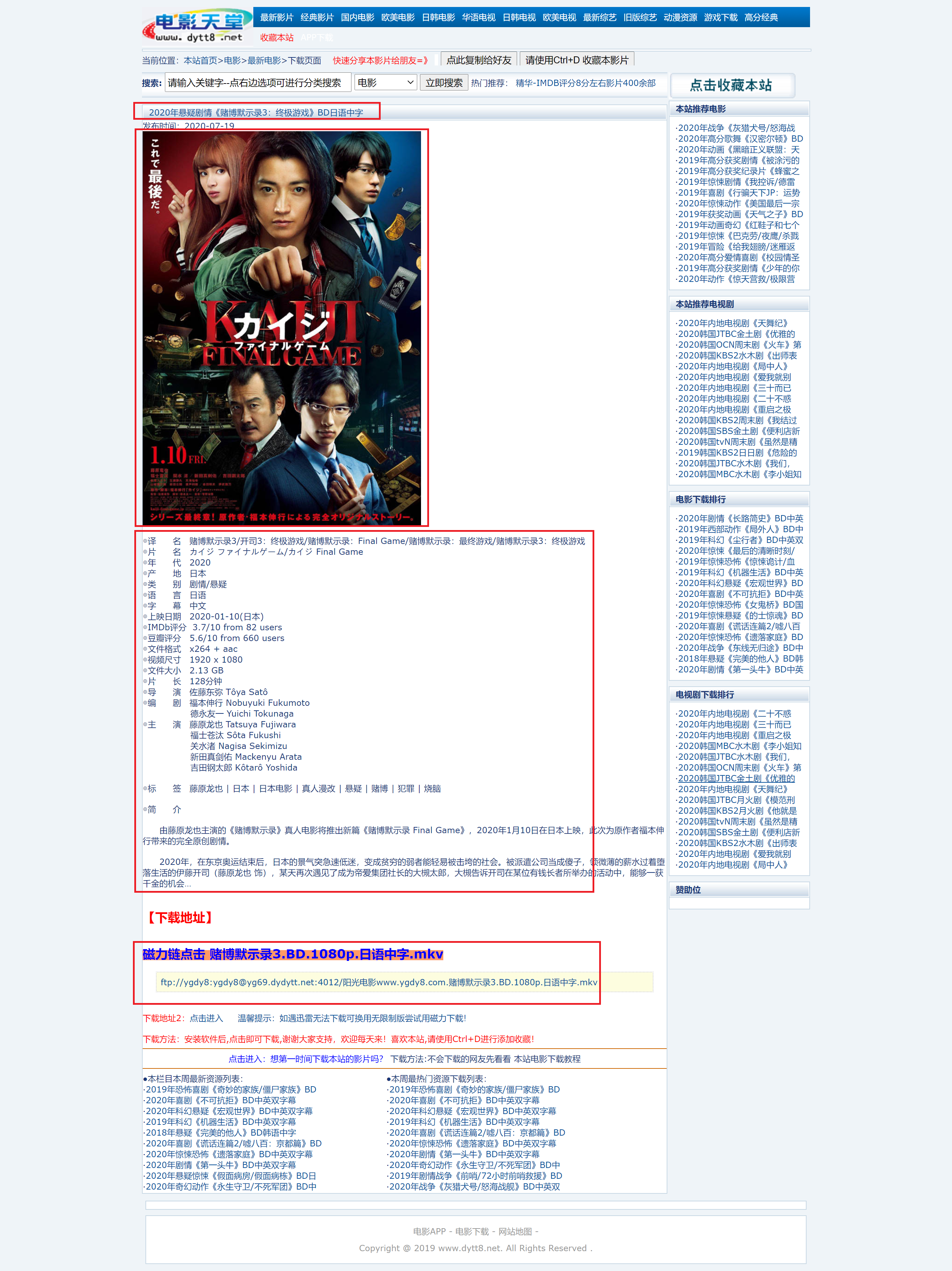
如果我们要获取电影天堂前七页中的电影的详细信息
红框中表示我们需要获取的信息:
url获取
首先考虑获取每一页电影的url,多点几个页面,发现有如下规律,当我们在第二页时,域名显示如下:
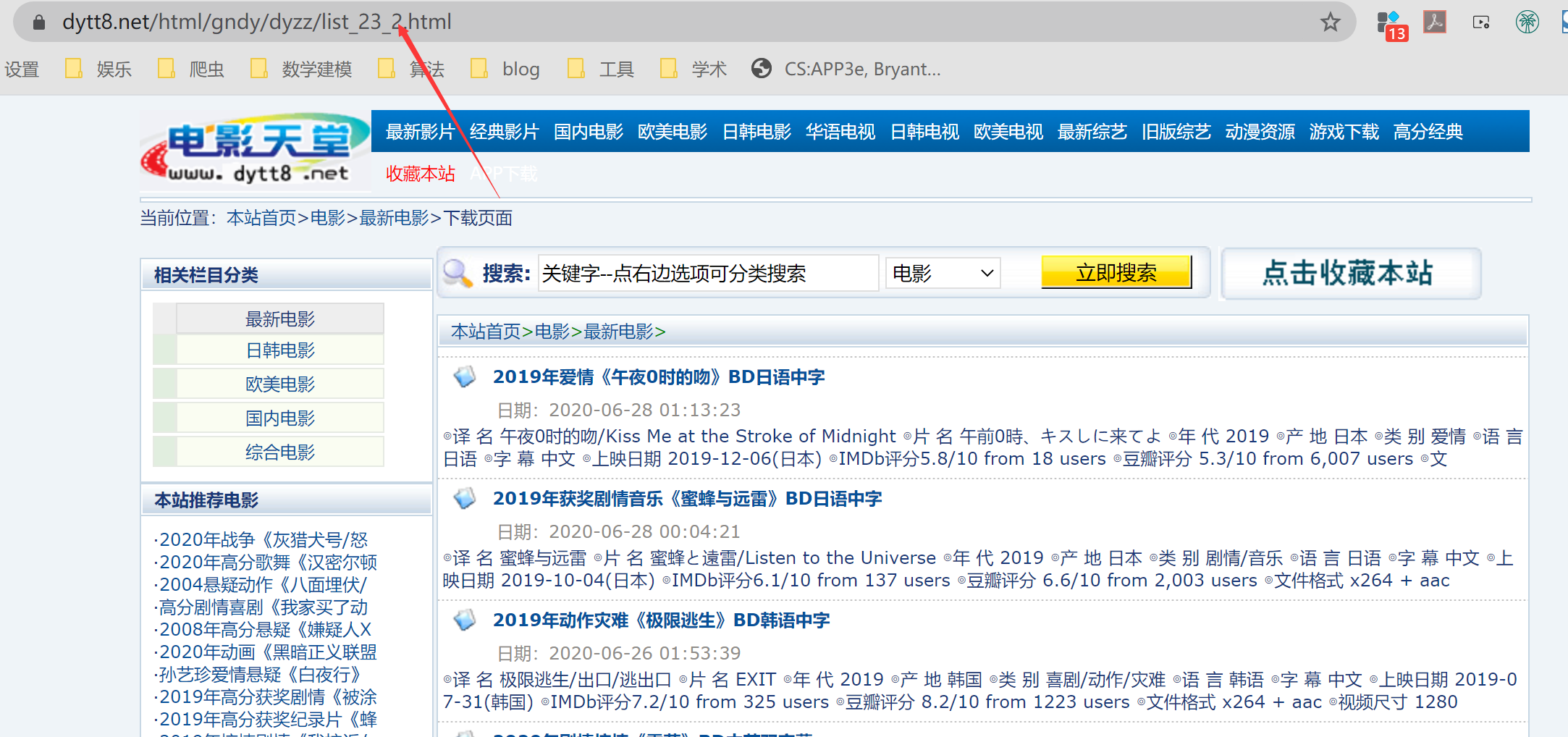
在第三页时,域名为:https://www.dytt8.net/html/gndy/dyzz/list_23_3.html
在第四页时,域名为:https://www.dytt8.net/html/gndy/dyzz/list_23_4.html
...
再从其他页面跳转到第一页时,域名为https://www.dytt8.net/html/gndy/dyzz/list_23_1.html
那么规律就很明显了,所以我们第一步应该是先要获取到每一中,电影的url,检查页面可知,a标签被放在一个table标签中,class为tbspan,所以可以根据这个来选择。
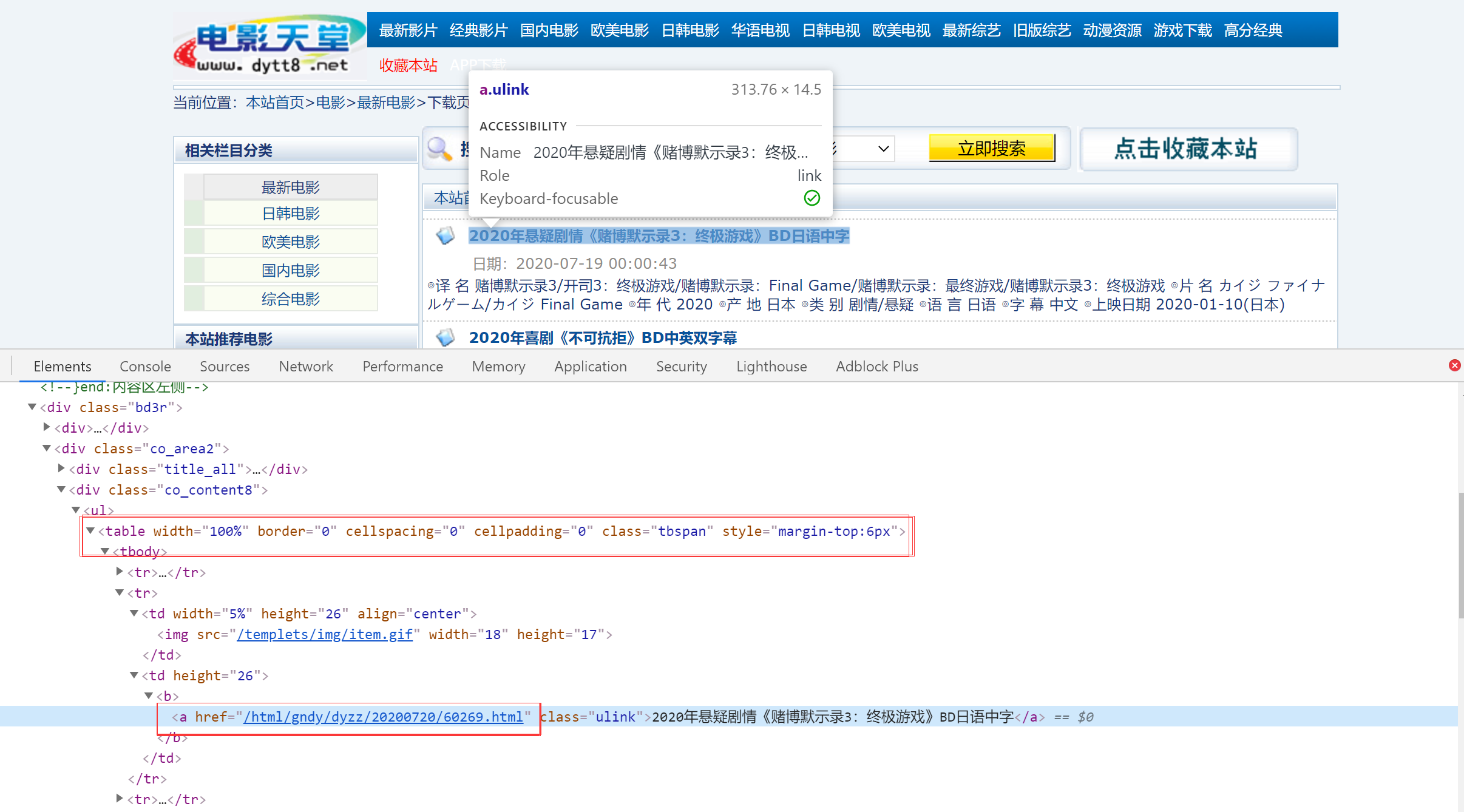
for index in range(1, 8):
url = 'https://www.dytt8.net/html/gndy/dyzz/list_23_' + str(index) +'.html' #页面的url
detail_urls = get_detail_urls(url) #获取当前页面中,所有电影的url
def get_detail_urls(url):
response = requests.get(url, headers = headers, verify = False)
text = response.content.decode('gbk', 'ignore') #由于电影天堂这个网站并不是很规范,用response.text的时候,会出现乱码,所以这里用content然后自己解码
# 构造htmlElement对象
html = etree.HTML(text)
detail_urls = html.xpath("//table[@class = 'tbspan']//a/@href") #获取url
#加上主域名
for index in range(len(detail_urls)): #看上图可知,获取到的url都只有后半截,所以我们需要手动加上前半截 BASE = 'https://www.dytt8.net'
detail_urls[index] = BASE + detail_urls[index]
return detail_urls
详情页获取
url获取完成之后,我们就需要根据这些url获取每一个电影详情页里面的东西了,包括电影名、海报封面、译名、片名、产地、简介、下载地址这些东西。
def start():
movies = []
for index in range(1, 8):
url = 'https://www.dytt8.net/html/gndy/dyzz/list_23_' + str(index) +'.html'
detail_urls = get_detail_urls(url) #当前页面的所有url拿到手
for detail_url in detail_urls: #对于每个url,也就是每一部电影
movie = parse_detail_page(detail_url) #解析详情页面,并返回解析的结果,这个函数后面会实现
movies.append(movie) #将电影信息保存在列表中
print(movie)
详情页解析:
首先看看详情页的信息,可以发现是非常的.......真的一点都不规范,所有的信息都被包裹在一个p标签中,所以获取信息非常麻烦
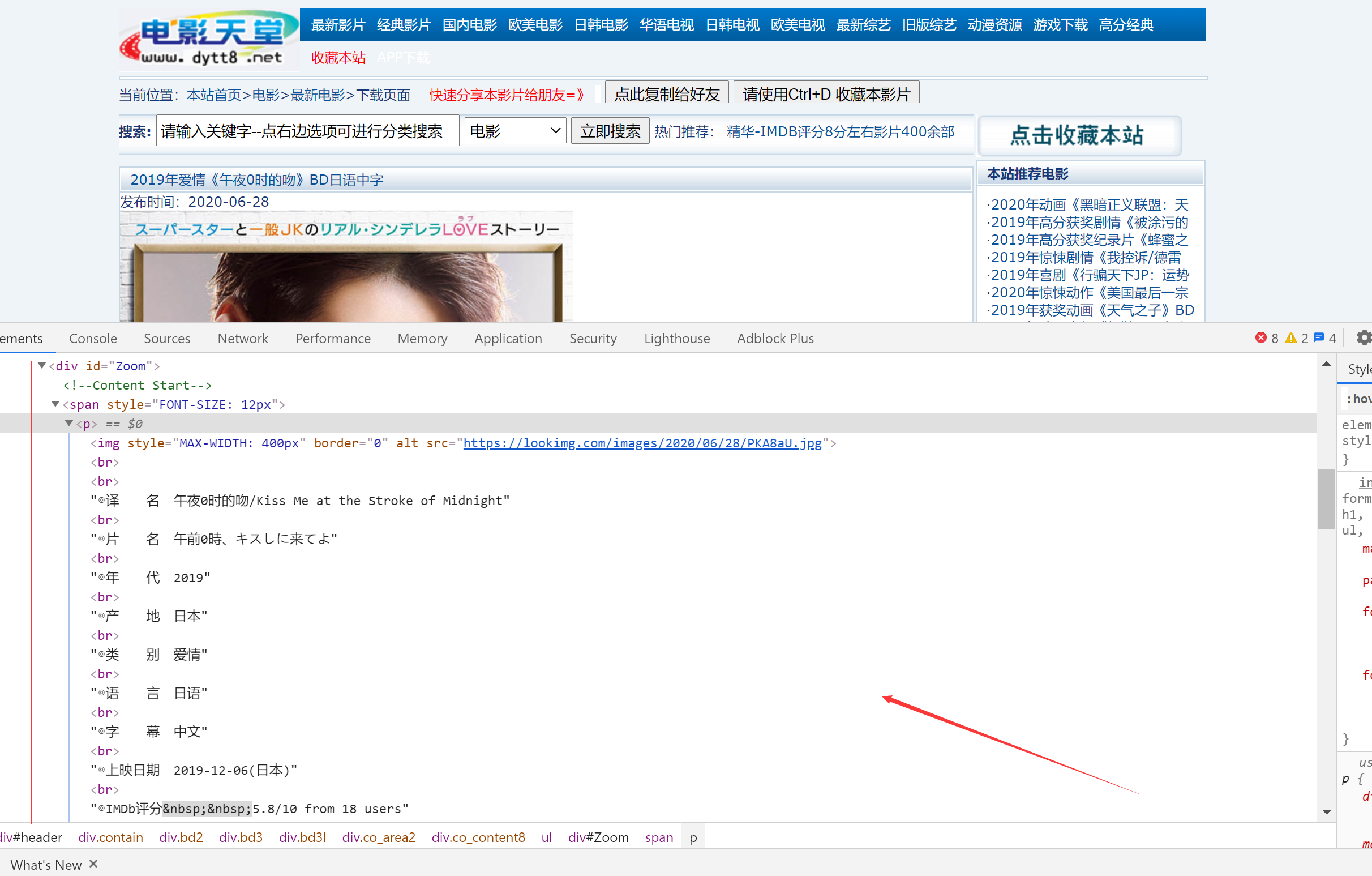
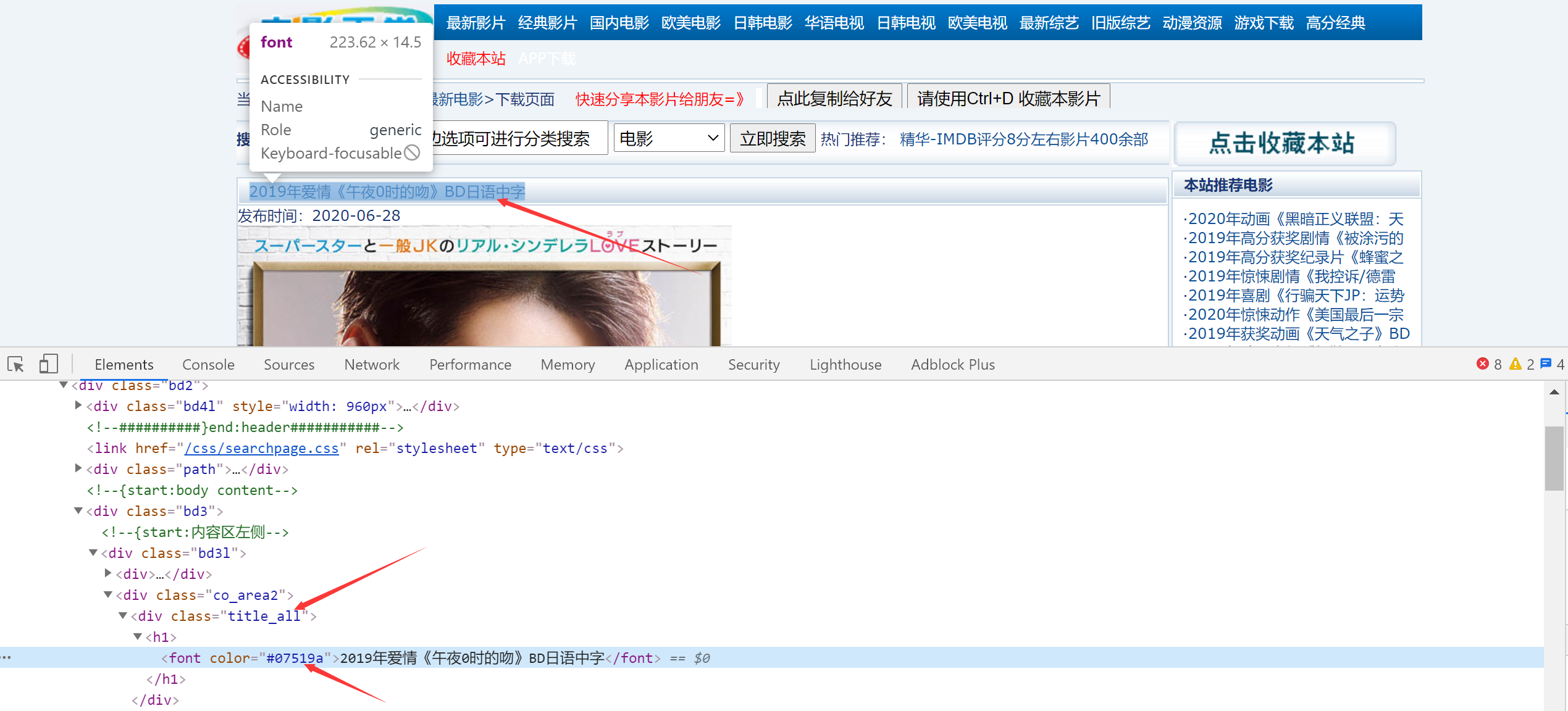
首先获取标题,根据class和font color来获取:
def parse_detail_page(url):
movie = {}
requests.packages.urllib3.disable_warnings()
response = requests.get(url, headers=headers, verify=False)
text = response.content.decode('gbk', 'ignore')
html = etree.HTML(text)
title = html.xpath("//div[@class = 'title_all']//font[@color = '#07519a']/text()")[0] #获取标题
movie['title'] = title
return movie
然后获取图片,根据Zoom和img来获取,图片这里要说一下,因为可能有的页面有两张图片:一个是海报封面post,另一个是电影截图screenshot,也有的页面一张post,没有screenshot,也有的都没有,所以我们获取了图片信息之后要先判断一下
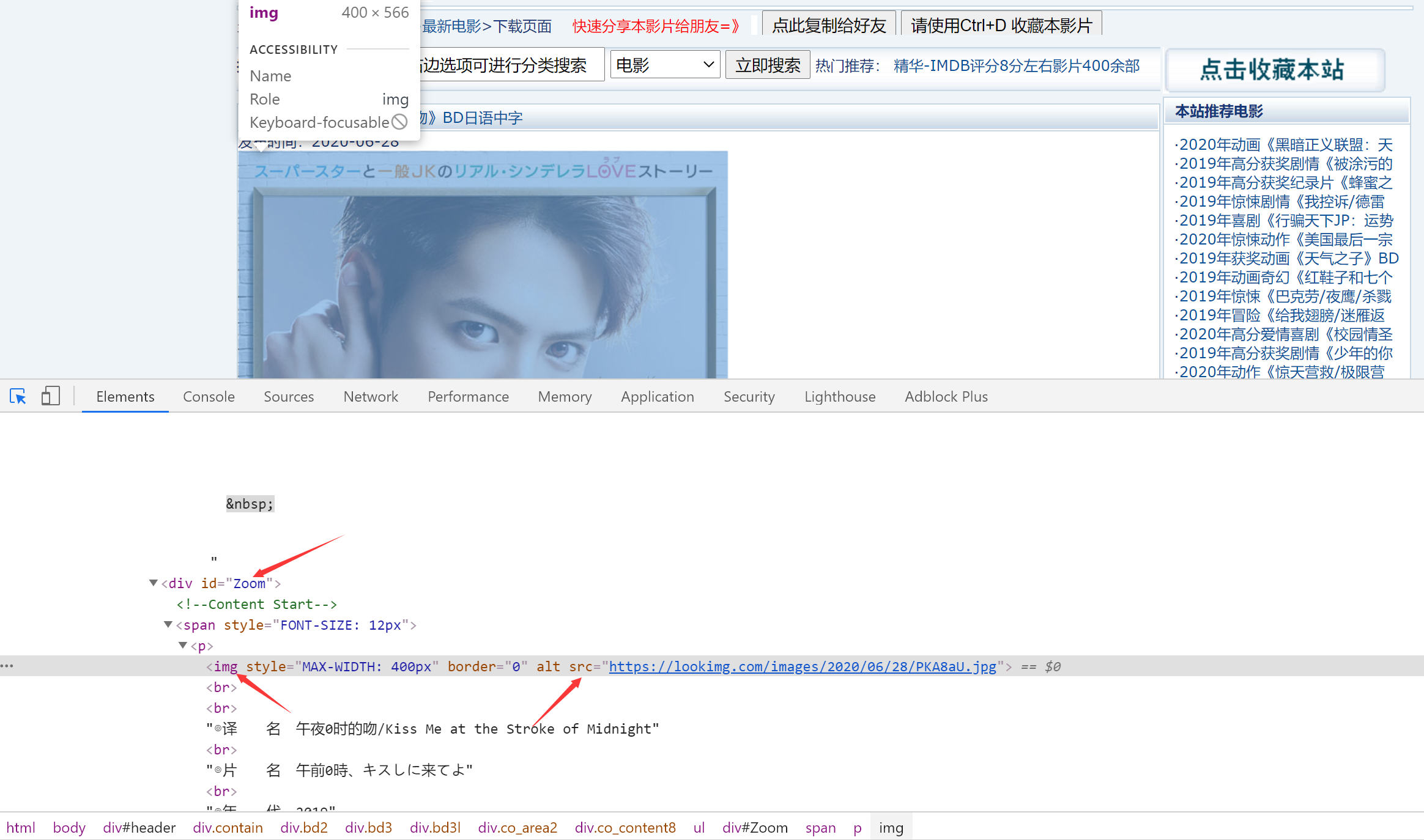
ZoomElement = html.xpath("//div[@id='Zoom']")[0]
photo = ZoomElement.xpath(".//img/@src")
if (len(photo) > 0): #如果photo这个列表中包含了图片,那就说明有海报:
movie['cover'] = photo[0]
else:
movie['cover'] = ""
if (len(photo) > 1): #如果photo包含了两张或两张以上的图片,则说明有截图
movie['screenshot'] = photo[1]
else:
movie['screenshot'] = ""
然后获取下方的文字信息:
infos = ZoomElement.xpath(".//text()") #看下方的注解1
def parse_info(info, rule):
return info.replace(rule, "").strip()
for index, info in enumerate(infos): #index为下标,info为内容
if info.startswith("◎年 代"): #如果是以年代开头
info = parse_info(info, "◎年 代") #那么将字符串中“◎年 代”这个字符使用replace函数替换为空格,然后使用strip函数去除前后空格
movie['year'] = info #最终得到的就是一个年份数字,没有乱七八糟的空格字符啥的
elif info.startswith("◎产 地"):
info = parse_info(info, "◎产 地")
movie['place'] = info
elif info.startswith("◎类 别"):
info = parse_info(info, "◎类 别")
movie['category'] = info
elif info.startswith("◎豆瓣评分"):
info = parse_info(info, "◎豆瓣评分")
movie['douban_rating'] = info
elif info.startswith("◎片 长"):
info = parse_info(info, "◎片 长")
movie['duration'] = info
elif info.startswith("◎导 演"):
info = parse_info(info, "◎导 演")
elif info.startswith("◎主 演"): #到主演这里需要注意,因为可能一部电影中有很多主演,看注解2
info = parse_info(info, "◎主 演") #首先处理第一行的主演,将其加入actor列表中
actors = [info]
for x in range(index + 1, len(infos)): #然后往后循环,只要不到◎这个符号,那就说明是主演,继续提取
actor = infos[x].strip()
if (actor.startswith("◎")):
break
actors.append(actor)
movie['actors'] = actors
elif info.startswith("◎简 介"):
info = parse_info(info, "◎◎简 介")
profile = [info]
for x in range(index + 1, len(infos)):
profile = infos[x].strip()
movie['profile'] = profile
download_url = html.xpath("//td[@bgcolor = '#fdfddf']/a/@href") #获取download链接
if len(download_url) > 0: #因为有的页面可能没有下载链接,所以判断一下
movie['download_url'] = download_url[0]
else:
movie['downloada_url'] = ""
注解1:使用ZoomElement下,使用text得到问题,会返回一个列表,列表中的一个元素,就是下图中的一行:
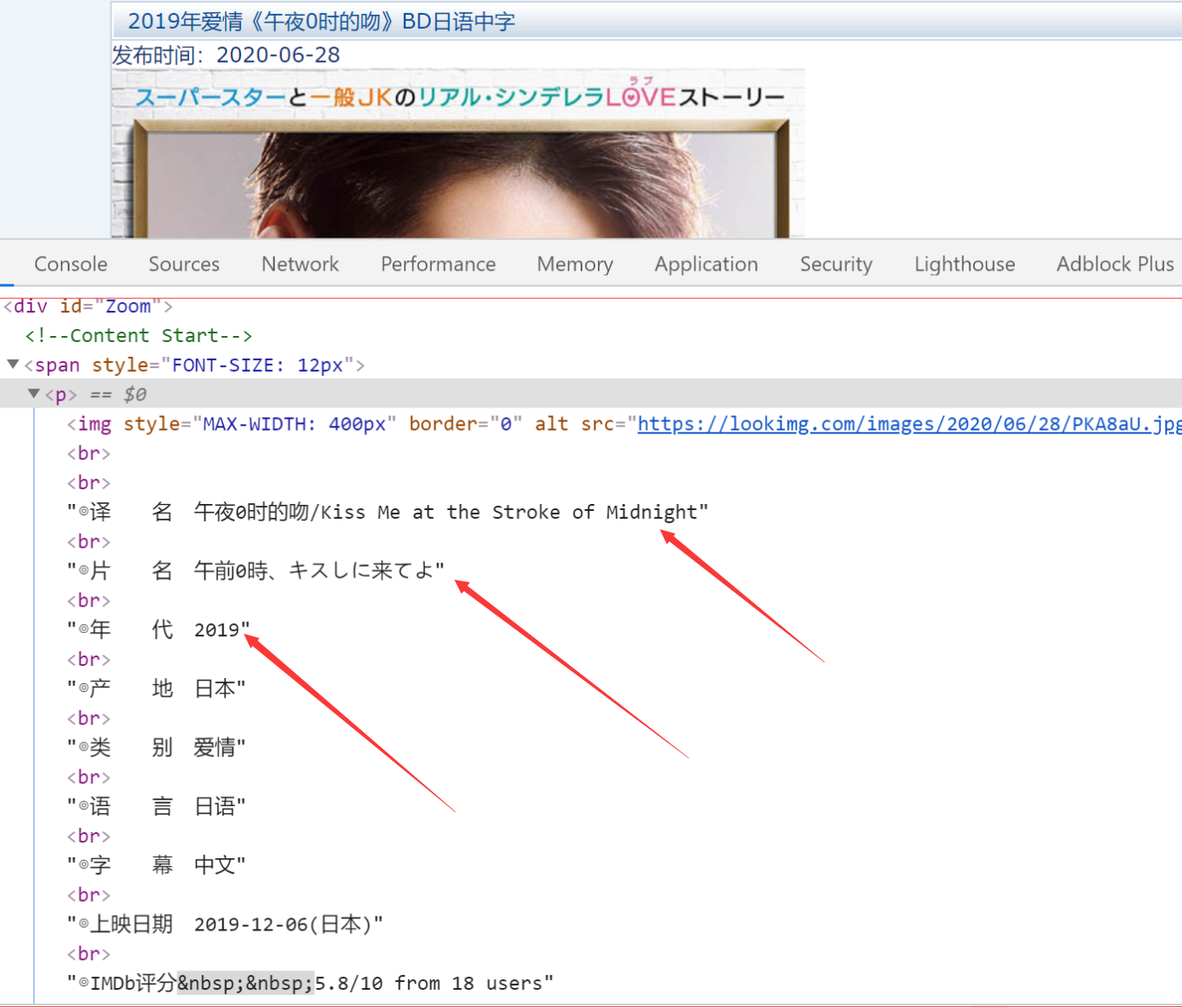
注解2:可能一部电影中有很多个主演,我们需要将所有的主演都保存下来

全部的代码
import requests
from lxml import etree
BASE = 'https://www.dytt8.net'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
def get_detail_urls(url):
response = requests.get(url, headers=headers, verify=False)
text = response.content.decode('gbk', 'ignore')
# 构造htmlElement对象
html = etree.HTML(text)
detail_urls = html.xpath("//table[@class = 'tbspan']//a/@href")
# 加上主域名
for index in range(len(detail_urls)):
detail_urls[index] = BASE + detail_urls[index]
return detail_urls
def parse_detail_page(url):
movie = {}
response = requests.get(url, headers=headers, verify=False)
text = response.content.decode('gbk', 'ignore')
html = etree.HTML(text)
title = html.xpath("//div[@class = 'title_all']//font[@color = '#07519a']/text()")[0]
movie['title'] = title
ZoomElement = html.xpath("//div[@id='Zoom']")[0]
photo = ZoomElement.xpath(".//img/@src")
if len(photo) > 0:
movie['cover'] = photo[0]
else:
movie['cover'] = ""
if len(photo) > 1:
movie['screenshot'] = photo[1]
else:
movie['screenshot'] = ""
infos = ZoomElement.xpath(".//text()")
def parse_info(info, rule):
return info.replace(rule, "").strip()
for index, info in enumerate(infos): #index为下标,info为内容
if info.startswith("◎年 代"): #如果是以年代开头
info = parse_info(info, "◎年 代") #那么将字符串中“◎年 代”这个字符使用replace函数替换为空格,然后使用strip函数去除前后空格
movie['year'] = info #最终得到的就是一个年份数字,没有乱七八糟的空格字符啥的
elif info.startswith("◎产 地"):
info = parse_info(info, "◎产 地")
movie['place'] = info
elif info.startswith("◎类 别"):
info = parse_info(info, "◎类 别")
movie['category'] = info
elif info.startswith("◎豆瓣评分"):
info = parse_info(info, "◎豆瓣评分")
movie['douban_rating'] = info
elif info.startswith("◎片 长"):
info = parse_info(info, "◎片 长")
movie['duration'] = info
elif info.startswith("◎导 演"):
info = parse_info(info, "◎导 演")
elif info.startswith("◎主 演"):
info = parse_info(info, "◎主 演")
actors = [info]
for x in range(index + 1, len(infos)):
actor = infos[x].strip()
if (actor.startswith("◎")):
break
actors.append(actor)
movie['actors'] = actors
elif info.startswith("◎简 介"):
info = parse_info(info, "◎简 介")
profile = [info]
for x in range(index + 1, len(infos)):
profile = infos[x].strip()
if profile.startswith('【下载地址】') :
break
movie['profile'] = profile
download_url = html.xpath("//td[@bgcolor = '#fdfddf']/a/@href")
if len(download_url) > 0:
movie['download_url'] = download_url[0]
else:
movie['downloada_url'] = ""
return movie
def start():
movies = []
for index in range(1, 8):
url = 'https://www.dytt8.net/html/gndy/dyzz/list_23_' + str(index) + '.html'
detail_urls = get_detail_urls(url)
for detail_url in detail_urls:
movie = parse_detail_page(detail_url)
movies.append(movie)
print(movie)
if __name__ == '__main__':
start()
运行结果:

由于request版本的原因,所以有些版本可能会报ssl证书错误(我在pycharm上可以跑,但是jupyter上面就不行),这个我找了好久也没找到解决方案,如果有大佬了解的话,可以告诉我一下^_^
Comments NOTHING