

当我们使用xpath、beautifulsoup或者正则表达式从请求的网页上解析完数据之后,如果我们之后还要用到这个数据的话,就需要将它们保存起来,本篇文章主要介绍如何读取并写入一些常用格式的文件,如:JSON、csv、excel,以及如何连接MySQL数据库,并对数据库进行操作。
JSON文件处理
JSON介绍
JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式。它基于 ECMAScript (w3c 制定的 js 规范)的一个子集,采用完全独立于编程语言的文本格式来存储和 表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言,而XML也就被淘汰了。 易于人阅读和编 写,同时也易于机器解析和生成,并有效地提升网络传输效率。
Json支持的格式
- 对象(类似与python中的字典)。使用花括号
- 数组(类似于python中的列表)。使用方括号
- 整性、浮点型、布尔类型和null类型
- 字符串类型(字符串必须要用双引号)
- 多个数据之间使用逗号分隔
- Note:json本质就是一个字符串
将字典和列表转换成JSON
在python中,只有基本数据类型才能转换成JSON格式的字符串。基本数据类型包括:int、float、str、list、dist和tuple。
(1)不写入文件,直接进行转换:json.dumps
import json
school = [
{
'name':'华中科技大学',
'type':'偏理'
}, {
'name':'武汉大学',
'type':'偏文'
}
]
print(type(school))
# 输出:<class 'list'>
json_str = json.dumps(school) #转换成json的字符串
print(type(json_str))
# 输出:<class 'str'>
print(json_str) # 输出:[{"name": "\u534e\u4e2d\u79d1\u6280\u5927\u5b66", "type": "\u504f\u7406"}, {"name": "\u6b66\u6c49\u5927\u5b66", "type": "\u504f\u6587"}]可以看到,输出了很多奇怪的编码,这是因为json在dump的时候,只能存放ascii字符,所以会将中文转义,解决的方法是使用ensure_ascii = False关闭这个特性:
json_str = json.dumps(school, ensure_ascii = False) #转换成json的字符串
print(type(json_str))
# 输出:<class 'str'>
print(json_str) #输出:[{"name": "华中科技大学", "type": "偏理"}, {"name": "武汉大学", "type": "偏文"}]里面的字符串都变成双引号了
(2)写入文件:json.dump,与前面的差别是少了一个s
import json
school = [
{
'name':'华中科技大学',
'type':'偏理'
}, {
'name':'武汉大学',
'type':'偏文'
}
]
with open ('school.json','w',encoding='utf-8') as f:
json.dump(school, f, ensure_ascii = False) #第二个参数就是要写入的文件指针注意:如果这里面的传入有中文,那么我们的文件编码要改成utf-8,而且,这里的ensure_ascii也要关闭
JSON字符串转换成python对象
(1)将一个json字符串load成Python对象:json.loads
import json
json_str = '[{"title": "钢铁是怎样练成的", "price": 9.8}, {"title": "红楼梦", "price": 9.9}]'
books = json.loads(json_str, encoding='utf-8')
print(type(books))
print(books)(2)从文件中读取json:
import json
with open('school.json', 'r', encoding='utf-8') as fp:
json_str = json.load(fp)
print(json_str)
输出:[{'name': '华中科技大学', 'type': '偏理'}, {'name': '武汉大学', 'type': '偏文'}]
这里指定编码为utf-8是因为这个文件是以utf-8存储的
csv文件处理
csv介绍
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本),在实践中,术语“CSV”泛指具有以下特征的任何文件:
- 纯文本,使用某个字符集,比如ASCII、Unicode、EBCDIC或GB2312(简体中文环境)等;
- 由记录组成(典型的是每行一条记录);
- 每条记录被分隔符(英语:Delimiter)分隔为字段(英语:Field (computer science))(典型分隔符有逗号、分号或制表符;有时分隔符可以包括可选的空格);
- 每条记录都有同样的字段序列。
读取csv文件
如果我们需要读取一个csv文件内的数据,可以使用如下的方式:
import csv
with open('文件.csv', 'r') as fp: #声明文件指针
reader = csv.reader(fp) #创建一个reader迭代器,之后我们想读取文件数据直接通过reader就好了
titles = next(reader) #如果加这一行,则不输出表头
,也就是指针往下挪一位
for item in reader: #遍历每一行
print(item) #输出每一行注意:这里可以不用指定文件的编码方式,一般windows下默认为gbk
可以发现,python将每一行都放在了一个列表中,我们可以通过操作列表下标的方式来提取数据。
import csv
with open('stock.csv', 'r') as fp:
reader = csv.reader(fp)
next(reader)
for item in reader:
name = item[3] #第四列
volumn = item[-1] #最后一列
print({'name':name, 'volumn':volumn})输出如下:

但是,如果想在获取数据的时候,通过标题来获取,那么可以使用DicReader。它将把每一行放到字典里面。(有序字典,返回的不包括标题栏)
import csv
with open('stock.csv', 'r') as fp:
reader = csv.DictReader(fp)
next(reader)
for item in reader:
secShortName = item['secShortName'] #secShortName这一列
turnoverVol = item['turnoverVol'] #turnoverVol这一列
print({'secShortName':secShortName, 'turnoverVol':turnoverVol}) 
写入csv文件
写入数据到 csv 文件,需要创建一个 writer 对象,主要用到两个方法。一个是 writerow, 这个是写入一行。一个是 writerows,这个是写入多行。示例代码如下:
import csv
headers = ['name','age','classroom']
values = [
('mach4101',21,'6'),
('machine',20,'6'),
('vsbf',18,'19')
]
with open('test.csv','w', newline='') as fp: #newline不指定的话,默认为\n,在行与行之间可能存在多余的空行
writer = csv.writer(fp) #创建一个writer对象
writer.writerow(headers) #将这一行写进去
writer.writerows(values) #将多行数据写进去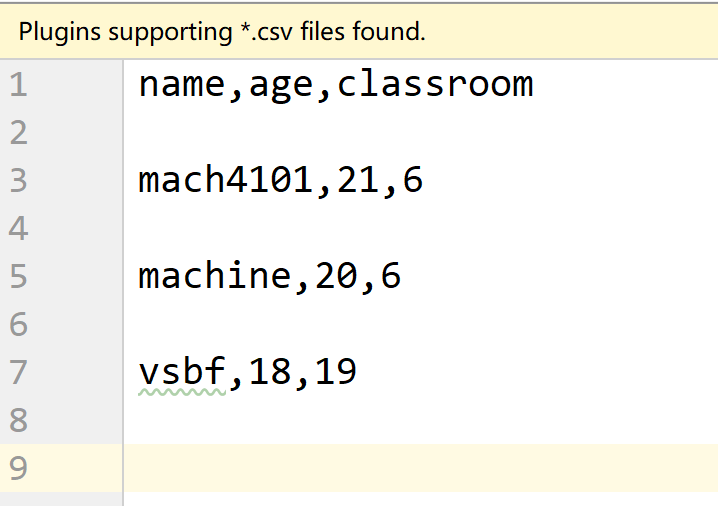
也可以使用字典的方式把数据写入进去。这时候就需要使用DictWriter了。示例代码如下:
import csv
headers = ['name','age','classroom']
values = [
{"name":'machine',"age":20,"classroom":'222'},
{"name":'mach4101',"age":21,"classroom":'333'}
]
with open('test.csv','w',newline='') as fp:
writer = csv.DictWriter(fp,headers) #DictWriter需要传递两个参数,文件指针和表头信息
writer.writeheader() #将表头写入文件
writer.writerow({'name':'vsbf',"age":18,"classroom":'111'})
#写入一行
writer.writerows(values) #写入多行Excel文件处理
在爬虫开发中,我们主要关注Excel文件的读写,不会过多关心Excel中的一些样式。如果想要读写Excel文件,需要借助到两个库xlrd和xlwt,其中xlrd是用于读的,xlwt是用于写的,安装命令如下:
pip install xlrd
pip install xlwt读取文件
import xlrd
workbook = xlrd.open_workbook("文件名.xlsx")
sheet_names = workbook.sheet_by_name()
print(sheet_names) #打印所有sheet的名称获取Sheet
一个Excel中可能有多个Sheet,那么可以通过以下方法获取想要的Sheet信息
- sheet_names:获取所有sheet的名字
- sheet_by_index:根据索引获取sheet对象,从0开始,也就是excel左下角的顺序
- sheet_by_name:根据名获取sheet对象
- sheets:获取所有sheet对象
- sheet.nrows:这个sheet中的行数
- sheet.ncols:这个sheet中的列数
实例代码:
import xlrd
workbook = xlrd.open_workbook("文件名.xlsx")
sheet_names = workbook.sheet_names()
print(sheet_names) #打印所有的sheet的名称
# 根据索引获取sheet
sheet = workbook.sheet_by_index(0)
print(sheet.name)
# 根据名称获取sheet
sheet = workbook.sheet_by_name("sheet名称")
print(sheet.name)
# 获取所有的sheet对象
sheets = workbook.sheets()
for sheet in sheets:
print(sheet.name)
# 获取这个sheet中的行数和列数
nrows = sheet.nrows
ncols = sheet.ncols获取Cell及其属性
Cell就是我们所谓的单元格,以下方法可以方便获取想要的Cell:
- sheet.cell(row, col):获取指定行和列的cell对象
- sheet.row_slice(row, start_col, end_col) :获取指定行的某几列cell对象
- sheet.col_slice(col, start_row, end_row):获取指定列的某几行cell对象
- sheet.cell_value(row, col):获取指定多个行和列的值
- sheet.row_values(row, start_col, end_col):获取指定行的某几列的值
- sheet.col_values(col, start_row, end_row):获取指定列的某几行的值
用到的数据:
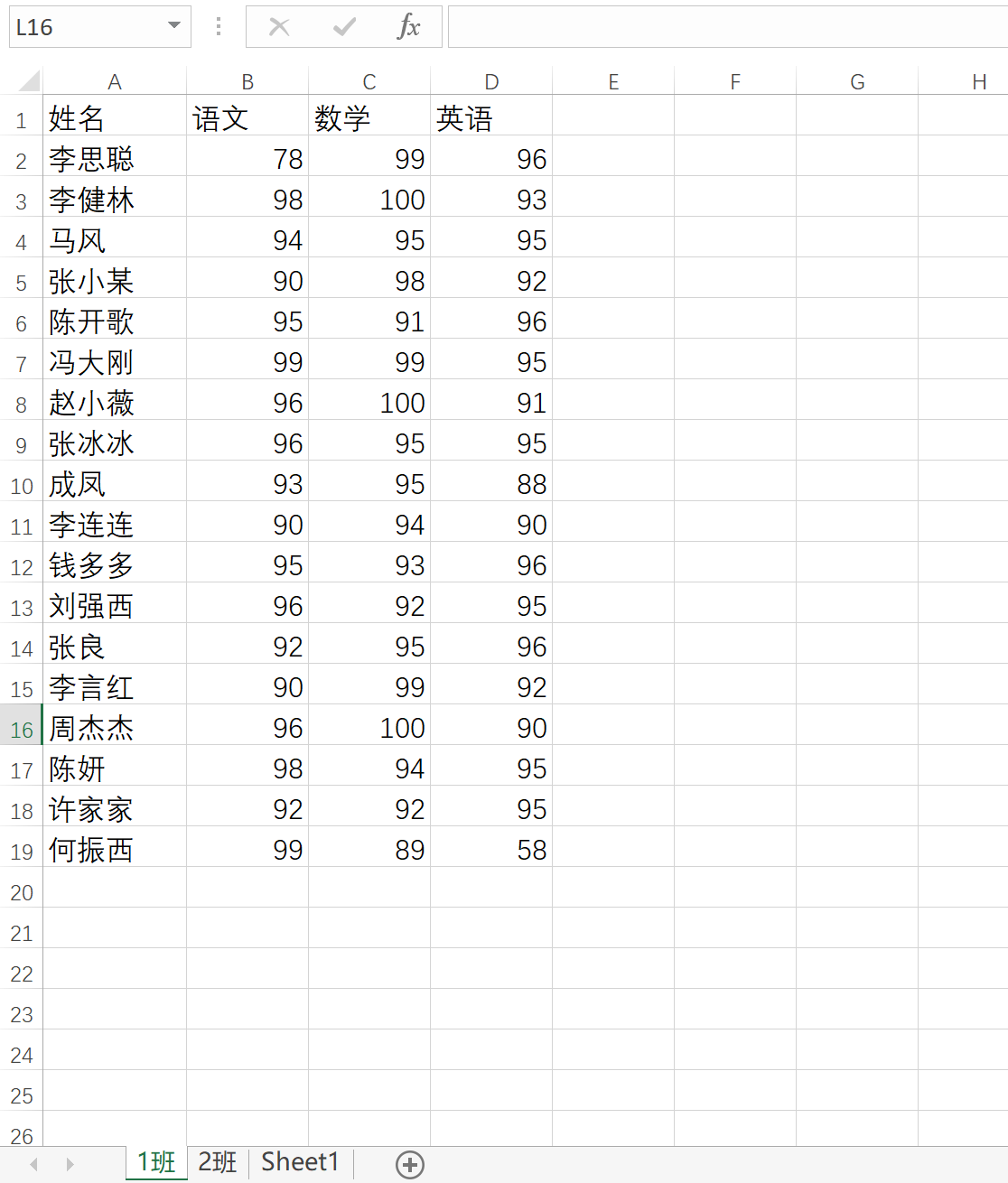
示例代码:
import xlrd
workbook = xlrd.open_workbook("成绩表.xlsx")
sheet = workbook.sheet_by_index(0)
#获取所有的cell对象
for col in range(sheet.ncols) :
for row in range(sheet.nrows) :
print(sheet.cell(row, col))
#使用sheet.row_slice获取第零行,第一列到第二列的cell对象,这里是前闭后开区间
cells = sheet.row_slice(0, 1, 3)
print(cells)
#使用sheet.col_slice获取第零列,第一行到第二行的cell对象
cells = sheet.col_slice(0, 1, 3)
print(cells)在cell上也有一些常用的属性:
- cell.value:这个cell里面的值
- cell.ctype:这个cell的数据类型
Cell的数据类型
- xlrd.XL_CELL_TEXT(Text):文本类型
- xlrd.XL_CELL_NUMBER(Number):数值类型
- xlrd.XL_CELL_DATE(Date): 日期时间类型
- xlrd.XL_CELL_BOOLEAN(Bool):布尔类型
- xlrd.XL_CELL_BLANK:空白数据类型
import xlrd
workbook = xlrd.open_workbook("成绩表.xlsx")
sheet = workbook.sheet_by_index(0)
cell = sheet.cell(0, 0);
print(cell.ctype)
cell = sheet.cell(1, 1);
print(cell.ctype)
print("=" * 30)
print(xlrd.XL_CELL_TEXT)
print(xlrd.XL_CELL_NUMBER)
print(xlrd.XL_CELL_DATE)
print(xlrd.XL_CELL_BOOLEAN)
print(xlrd.XL_CELL_BLANK)
运行发现前面的部分分别输出了1和2,说明1就表示文本,2表示数字,后面部份就是各类型所代表的数字
写入Excel:
步骤如下:
- 导入xlwt模块
- 创建一个Workbook对象
- 创建一个Sheet对象
- 使用sheet.write(row, col, data)方法把数据写入到Sheet下指定的行和列中,如果想在原来的workbook对象上添加新的cell,那么需要调用put_cell来添加
- 保存成Excel文件
示例代码:
import xlwt
import random
workbook = xlwt.Workbook(encoding= 'utf-8')
sheet = workbook.add_sheet('成绩表')
headers = ['数学','英语', '语文']
for index, header in enumerate(headers): #将表头信息写入
sheet.write(0, index, header)
for row in range (1, 10): #将数据写入到表中
for col in range(3):
grade = random.randint(0, 100) #生成0到100的随机数
sheet.write(row, col, grade) #写入
workbook.save("abs.xls")生成的东西:
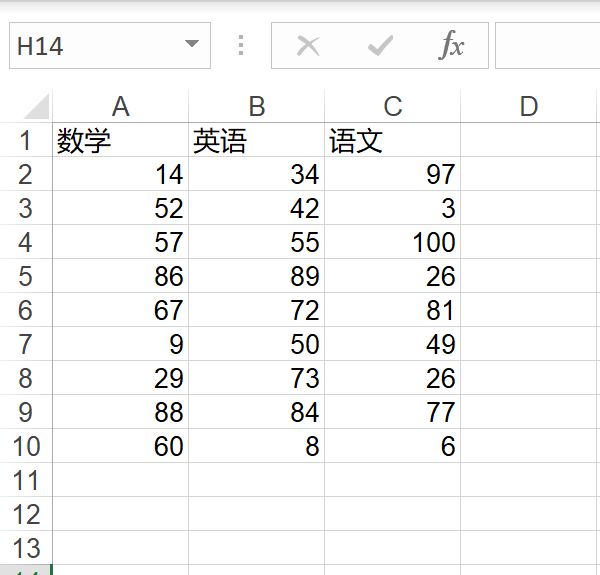
如果要在已经存在的excel中加入新的列或者新的行,那么需要使用`put_cell(row, col, type, value, xf_index)`来添加进去,最后再放到xlwt创建的workbook中,然后再保存进去,示例代码如下:
import xlrd
import xlwt
workbook = xlrd.open_workbook("成绩表.xlsx")
rsheet = workbook.sheet_by_index(0)
#添加总分成绩
rsheet.put_cell(0,4,xlrd.XL_CELL_TEXT,"总分",None)
for row in range(1, rsheet.nrows) :
grade = sum(rsheet.row_values(row, 1, 4)) #row这一行,第一列到第四列的总成绩
rsheet.put_cell(row, 4, xlrd.XL_CELL_NUMBER, grade, None)
#添加每个科目的平均成绩
# rsheet.put_cell(19,0, xlrd.XL_CELL_TEXT,"平均分",None)
total_rows = rsheet.nrows
total_cols = rsheet.ncols
for col in range(1, total_cols) :
grades = rsheet.col_values(col, 1, total_rows) #对于每一列,求每行的和
avg_grade = sum(grades) / len(grades) #计算平均
rsheet.put_cell(total_rows, col, xlrd.XL_CELL_NUMBER, avg_grade, None) #写入数据
#重新写入一个新的excel文件
new_workbook = xlwt.Workbook(encoding='utf-8')
new_sheet = new_workbook.add_sheet('成绩')
for row in range(rsheet.nrows):
for col in range(rsheet.ncols):
new_sheet.write(row, col, rsheet.cell_value(row, col)) #将数据从rsheet中写入到newsheet中
new_workbook.save("新的成绩表.xls")数据插入后,效果如下:
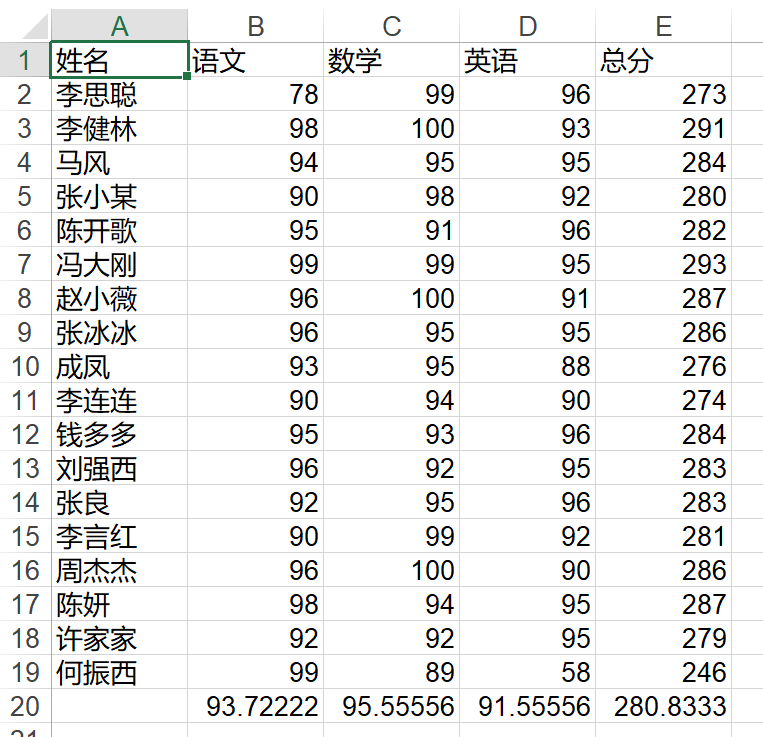
这个程序有一个bug就是,如果我想将'平均分'插入到第20行第一列时,会报错,所以这里我没有插入。
使用Python连接MySql
首先需要安装驱动程序:Python要想操作MySQL。必须要有一个中间件,或者叫做驱动程序。驱动程序有很多。比如有mysqldb、mysqlclient、pymysql等。在这里,我们选择用pymysql。安装方式也是非常简单,通过命令pip install pymysql即可安装。
安装完成之后就可以开始了
连接数据库
import pymysql
db = pymysql.Connect(host = "localhost",
#创建一个连接对象
user = "root",
password = "你的密码",
database = "你要用到的数据库名称",
port = 3306)
cursor = db.cursor()
# 创建游标
cursor.execute("select 1")
#执行sql命令
result = cursor.fetchone()
#取一行值
print(result)
#将取出来的这一行值输出
cursor.close()
#关闭游标如果输出了(1, )就表示成功了
插入已知数据
import pymysql
db = pymysql.Connect(host = "localhost",
user = "root",
password = "你的数据库密码",
database = "你用到的数据库名",
port = 3306)
cursor = db.cursor()
sql = """
insert into user (uid, username, passwd) values (null, "sbf", "hhh") #
sql语句
"""
cursor.execute(sql)
#执行命令
db.commit()
#对数据库进行的修改操作一定要提交,否则就不会改变数据库里面的内容
db.close()
#关闭游标插入未知数据
其实就是把变量插入到数据库中:
import pymysql
db = pymysql.Connect(host = "localhost",
user = "root",
password = "你的数据库密码",
database = "你用到的数据库名",
port = 3306)
cursor = db.cursor()
sql = """
insert into user (uid, username, passwd) values (null, %s, %s)
""" #通过变量来传参数,注意这里,即使传递的是数字,也要用%s,而不是%d
username = "woee" #标记1
passwd = "iee" #标记2
cursor.execute(sql, (username, passwd)) #这里要用元组,把标记1和标记2中内容传递给sql语句中的%s
db.commit()
cursor.execute("select * from user")
result = cursor.fetchall()
print(result)
db.close()
如果在数据不能保证的情况下,还可用下面的方式插:
sql = """
insert into user(
id,username,gender,age,password
)
values(null,%s,%s);
"""
cursor.execute(sql,('woee','ieeeee')) #直接传递常量到%s,这里一定要用元组查询操作
当我们执行完sql的查询语句之后,数据会保存在游标(cursor)中,我们可以使用游标对象的函数来提取数据:
- fetchone(),每次提取一条数据
- fetchall(),提取所有数据
- fetchmany(size),每次提取size条数据
实例代码:
import pymysql
db = pymysql.Connect(host = "localhost",
user = "root",
password = "你的数据库账户密码",
database = "你用到的数据库名称",
port = 3306
)
cursor = db.cursor()
sql = """
select * from user
"""
cursor.execute(sql)
while True: #每次提取一条数据
result = cursor.fetchone()
if result : #如果result不为空,说明提取到了数据,那就输出
print(result)
else: #否则,说明数据被我们提干了,就结束
break
db.close()这种方法比较麻烦,我们直接用fetchall:
import pymysql
db = pymysql.Connect(host = "localhost",
user = "root",
password = "你的数据库账户密码",
database = "你用到的数据库名称",
port = 3306
)
cursor = db.cursor()
sql = """
select * from user
"""
cursor.execute(sql)
results = cursor.fetchall()
for result in results:
print(result)
db.close()当然,也可以使用fetchmany,就和上面一样,用循环输出列表中的元素就好了
删除操作
没啥好说的,就是执行sql语句,然后提交就好了
cursor = db.cursor()
sql = """
delete from user where id=1
"""
cursor.execute(sql)
db.commit()
db.close()更新操作
也是执行操作,然后提交,主要还是在于sql语句的写法,如果你感觉sql语句写起来有压力的话,不妨去看看本人在博客中分享的数据库实验,做完保证你sql上一个台阶。
import pymysql
db = pymysql.Connect(
host = "localhost",
user = "root",
password = "你的数据库账户密码",
database = "你用到的数据库名称",
port = 3306
)
cursor = db.cursor()
sql = """
update user set username = "hhhhhhhhhh" where uid = 2
"""
cursor.execute(sql)
db.commit()数据库就说到这里了,其实一般来讲爬海量数据的话,MongoDb的性能会比Mysql高不少,但是我没有学过,所以这里先挖个坑,如果有必要再来填坑。
Comments NOTHING