

也是准备边缘计算课程汇报所读的论文,上一篇感觉有点难讲,随机模型什么的我没有接触过,换了篇简单的,内容如下:
摘要
云计算的兴起促进了应用程序的爆炸性增长,然而,随着前所未有的数据量和数据种类的快速产生,对低延迟的高质量移动服务的需求也在不断增加。边缘计算是一种新兴的范例,它在靠近用户的一侧设置了一些服务器,并允许一些实时请求在被这些靠近用户端的服务器处理后直接返回给用户。目前,工业界对边缘计算有两个主要问题。
- 一是减少任务的延迟
- 另一个是考虑耗电量的持久性
在本文中,我们专注于节省系统的功耗,以在移动边缘计算中提供一个高效的调度策略。我们的目标是在满足资源和延迟约束的同时,减少边缘节点提供者的功耗。我们首先通过基于睡眠功耗模式将边缘节点虚拟化为主节点和从节点来接近这个问题。之后,我们提出了一种通过平衡虚拟节点资源的调度策略,既减少了功耗,也保证了用户的延迟。我们使用iFogSim来模拟我们的策略。模拟结果显示,我们的策略可以有效地减少边缘系统的功耗。在空闲任务的测试中,最高能耗比原始算法低了27.9%。
1. INTRODUCTION
传统的云计算使用集中式的大容量集群设备来处理大量的信息。所有的计算过程都集中在云端,以便于数据的收集和共享。这催生了一系列的大数据应用。尽管云计算具有几乎无限的计算能力,但使用云计算不可避免地要承担大量的通信成本,这必然导致延迟。集中处理架构决定了用户的数据需要上传到云端进行处理,这使得延迟难以减少。然而,随着云计算的发展,虚拟现实(VR)、增强现实(AR)、实时视频、自动驾驶、智能医疗等实时应用的爆炸性增长,云计算的缺点变得越来越明显。实验表明,边缘计算是处理应用延迟需求的好方法。边缘计算架构被提出来解决云计算大延迟的问题。具体来说,边缘计算在靠近用户的一侧处理需要高延迟的任务,并将原本只能在云计算平台上处理的任务放入边缘服务器。由于边缘层的设备在功率和计算能力上有限,任务的不良资源分配将导致高延迟和高功耗。在本文中,我们专注于边缘计算中减少功耗问题。这个问题非常重要,主要是由于以下挑战:
- (i)由于物联网设备不断生成数据,且分析必须非常迅速。一个重要问题是找到一种边缘设备的调度策略,可以在较低的延迟内实现任务。
- (ii)边缘云架构中引入了部分电池供电的设备,如智能手机、笔记本电脑等。因此,另一个重要问题是考虑任务的资源分配,以减少功耗并实现电池的持久性。
在本文中,我们专注于节省系统的功耗,以提供移动边缘计算中的高效调度策略。我们的目标是在满足资源和延迟约束的同时,减少多个用户的功耗。我们的贡献可以总结如下:
- 我们首先实施了一个基于正态分布的任务生成模型,并增加了任务的最大可容忍延迟特性。我们引入了一种对边缘节点具有较低功耗的睡眠模式。
- 在此基础上,我们通过将边缘节点虚拟化为主节点和从节点来解决功耗减少问题,并提出了一种调度策略,通过平衡虚拟节点的资源既减少了功耗,也保证了用户的延迟。
- 我们使用iFogSim进行了各种模拟以测试我们的调度策略。结果从不同角度展示以提供结论。
本文的其余部分组织如下。第二节回顾相关工作。第三节描述模型,然后构建问题。第四节探讨移动用户的功耗降低问题,并介绍一种调度策略。第五节展示模拟和结果。最后,第六节总结本文。
2. RELATED WORK
作为一种新的范式,边缘计算被用来将云计算扩展到网络的边缘,从而使新一代的应用程序和服务成为可能。如今,许多论文都集中在边缘计算中的功耗问题上。
Taneja等人提出了一个基本的模块映射算法,通过在雾云基础设施中有效部署物联网应用的应用模块,高效利用网络基础设施中的资源。Barcelo等人认为能源消耗是当今网络和云运营成本的主要驱动因素,并根据与之相关的感测、计算、传输能力和能效特性,对物联网-云网络资源进行了分类。他们将物联网-云网络中的服务分布问题数学表述为最小成本混合转播流问题。黄振球等人提出了一种服务合并策略,用于在设备上映射和共置多个服务。他们使用整数规划在多跳网络中解决这个问题,并使用启发式算法来处理单跳网络中的同一个问题。Trinh和Trinh等人研究了移动边缘计算处理受限功率限制的物联网设备的能源管理相关应用的潜力,同时提供高分辨率视觉数据的低延迟处理。为了解决处理吞吐量和能源效率之间的权衡,他们提出了一种基于可持续策略算法的智能驱动边缘路由,该算法使用机器学习。Mavromoustakis等人通过使用M2M通信在密集网络系统中实现边缘计算范式提出了不同的方法,旨在为延迟敏感的服务提供可靠性。此外,张等人使用强化学习和博弈论来处理延迟或服务质量QoS问题。Dinh等人考虑了CPU固定频率和CPU可变频率两种情况下的任务调度问题。对于固定CPU频率,提出了基于线性松弛的方法和半确定性松弛的方法;对于CPU频率可调的情况,则使用基于穷举搜索的方法和基于SDR的方法。模拟结果显示,基于SDR的算法实现了近乎最优的性能。Gupta Trinh等人演示了通过使用iFogSim模拟器对物联网环境的建模和资源管理策略。此外,他们在不同情况下验证了RAM消耗和执行时间模拟工具的可伸缩性。
然而,以上工作仍然存在一些不足之处。例如,基于机器学习的调度策略和增加新的通信链路会增加边缘计算架构的负担。更重要的是,这些工作大多只集中在降低功耗上,但忽略了任务的最大可容忍延迟。这些研究都试图在调度算法上给出最佳解决方案,而没有尝试边缘设备本身的节能功能。本文提出了一种基于设备睡眠模式调度算法来减少边缘设备功耗的新思路。基于此,系统的整体功耗得到了降低,而不会增加边缘设备的功耗比率。
3. MODEL AND PROBLEM FORMULATION
3.1 Network model
网络模型由云层、边缘层和用户层组成,如图1所示。云和边缘节点通过网关和代理服务器进行通信。不同层之间使用无线或有线连接。基于这种层次结构,边缘系统与传统云的区别在于,用户请求的任务可能在靠近用户的边缘节点处理,并将处理结果返回给用户。在网络模型中,我们将一个边缘节点分为两个虚拟节点,即主节点和从节点。设$C$表示一个边缘节点的计算能力,$C_m$和$C_s$分别表示主节点和从节点的计算能力。
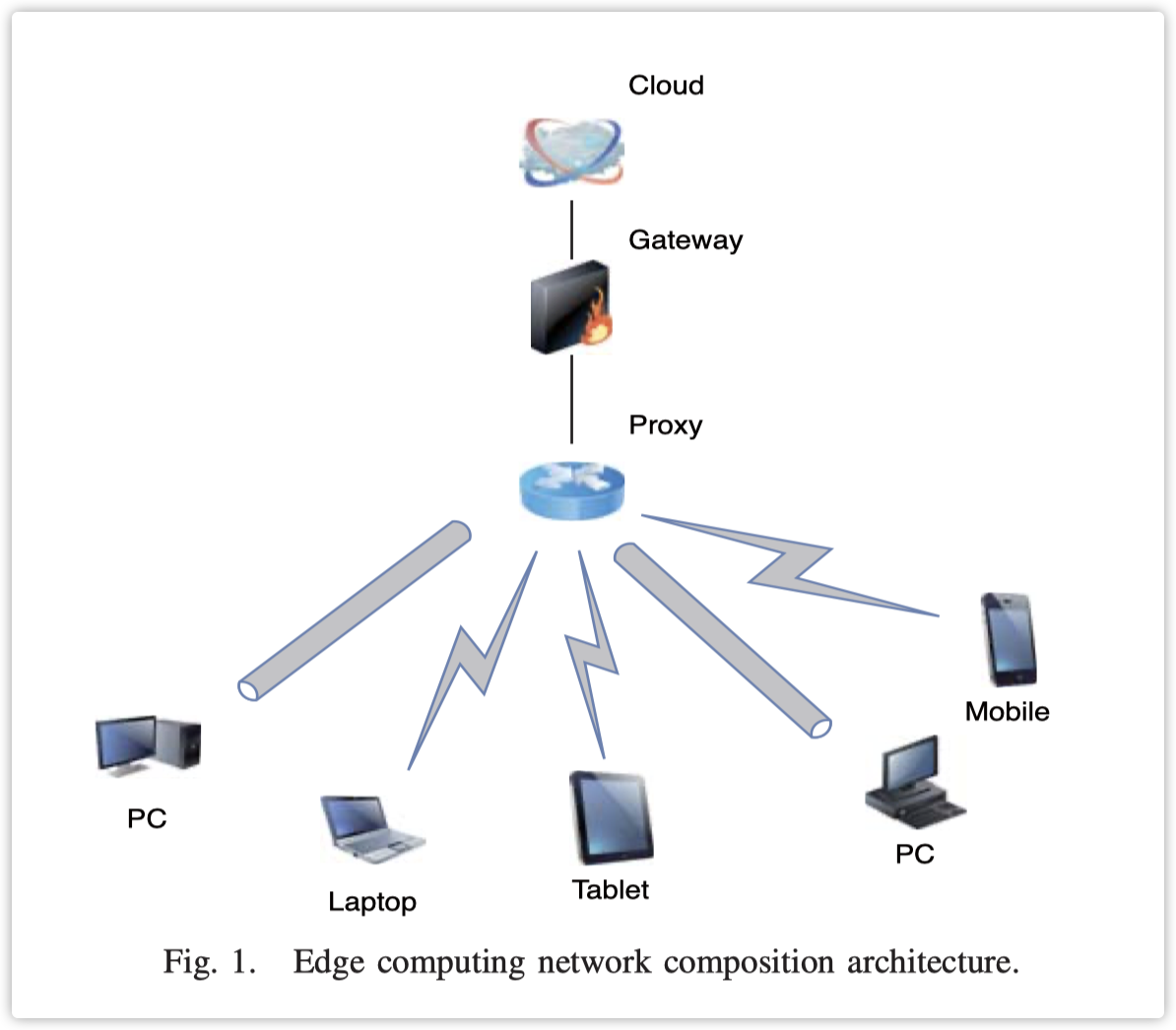
3.2 Power model
对于每个边缘节点,我们假设有两种不同的模式:活跃模式和睡眠模式。我们使用$P$来表示一个边缘节点的功率,其中包括两种模式,活跃模式$P_a$和睡眠模式$P_s$。活跃模式是边缘节点的高功率模式。只有在活跃状态下的设备才能执行任务,并且任务调度活动也是一种活动,需要活跃状态的支持。活跃模式下的功率消耗与CPU使用率呈线性关系,即$Pa = k·C + b$,其中$b$是边缘节点在空闲状态下的功率,$k$是符合边缘节点功率曲线的系数。
睡眠模式是边缘节点的一个非常低功率模式。在此模式下的设备通常只为内存和可以用于唤醒的相关设备保留功率。常用的唤醒设备包括网络卡、鼠标、键盘、电源按钮等。因为睡眠功率与处理器无关,所以所有三个平台上的睡眠功率是相同的。通常,睡眠状态的功率消耗极低。对于一般的个人电脑,这个功率消耗大约是4.5瓦。在本文中,我们使用这个参数来模拟睡眠状态下的功率消耗。
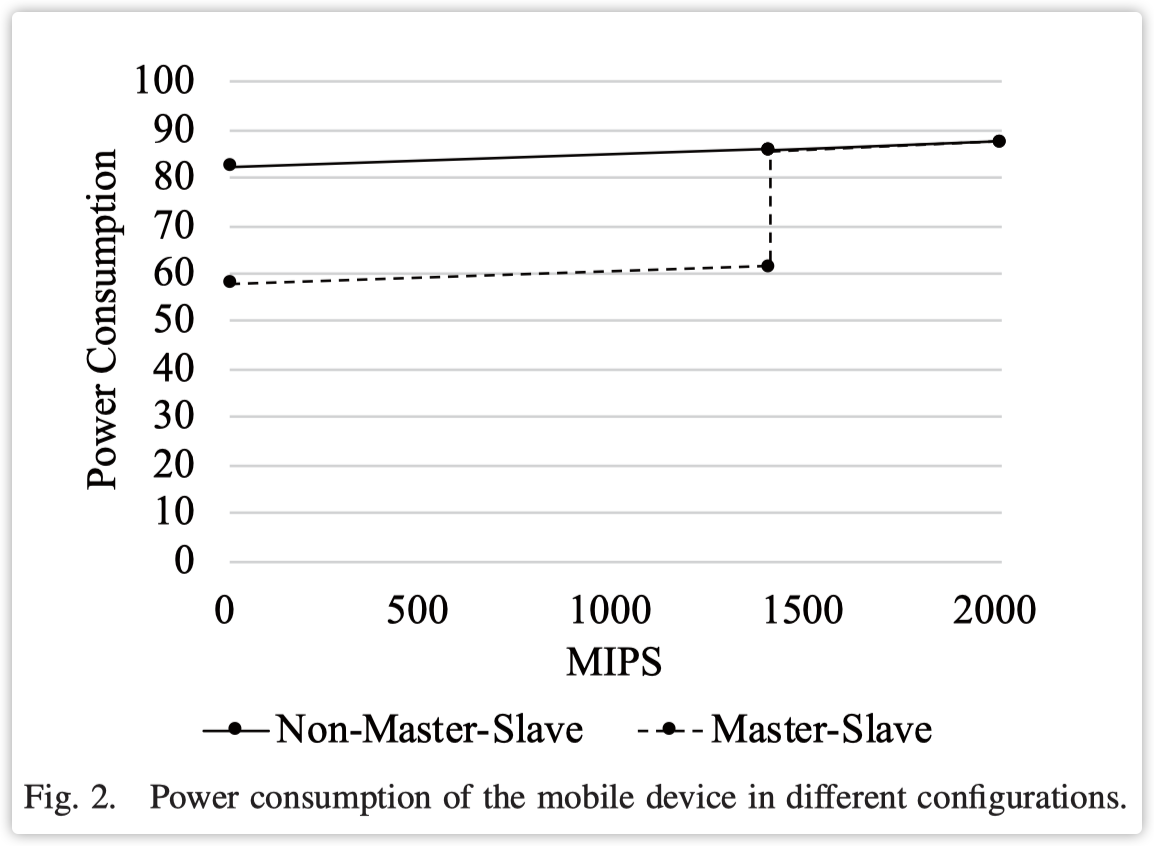
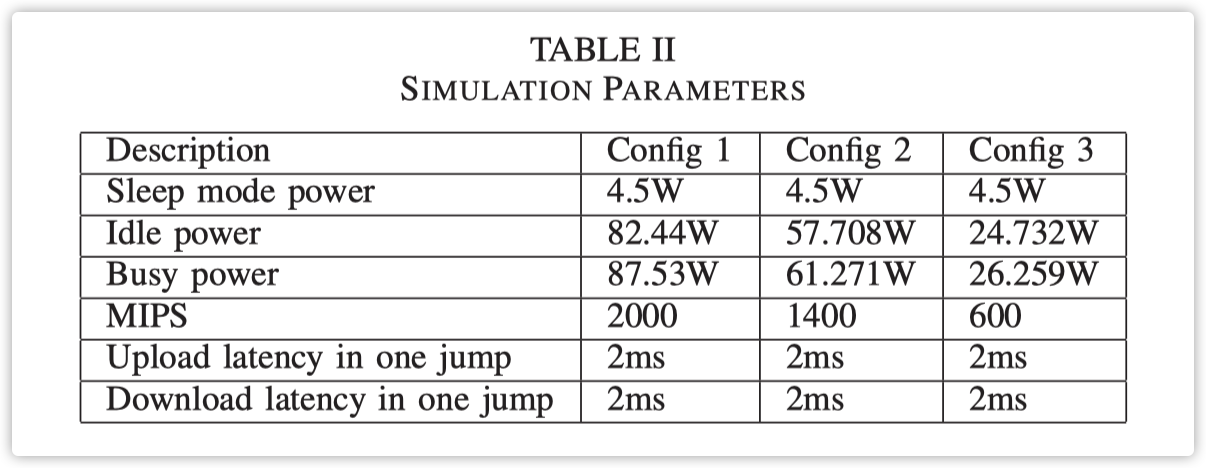
我们使用了三种不同的边缘设备。我们将Config 1视为原始设备。为了降低边缘节点的功率消耗,我们将原始设备分成了两个设备,Config 2和Config 3。为了确保公平性,我们保证Config 2和Config 3的MIPS之和等于Config 1 每秒百万指令数(MIPS,是一种衡量计算能力的单位)加起来的总和与另一个单独的配置(Config 1)的MIPS相等, 这样做是为了使得总体的计算能力在不同配置间保持一致,以便公正地评估它们的性能。。我们将仅有一个Config 1配置的设备组合称为非主从模式,每个都有Config 2和Config 3的组合称为主从模式。我们将主设备设置为Config 2,将从设备设置为Config 3。主设备用于任务调度和执行,从设备只执行任务,并在空闲时进入睡眠状态。后续的实验部分将基于这种配置。具体的实验步骤和结果可以参考第3节的第4部分。图2是边缘节点在两种不同策略下的功率消耗值,其中横轴是边缘节点的占用率,纵轴是节点的瞬时功率消耗。图2表明,在小于1400 MIPS时,主从组合的功率消耗远低于非主从模式。这是因为Config 2的设备正在运行,而Config 3的设备处于睡眠状态。在主从模式中,未收到任务的设备可以在没有计算任务需要时进入睡眠状态。处于睡眠状态的设备可以通过网络命令被其他设备唤醒。在非主从模式中,设备不能进入睡眠状态,因为节点中只有一个设备。
3.3 Task model
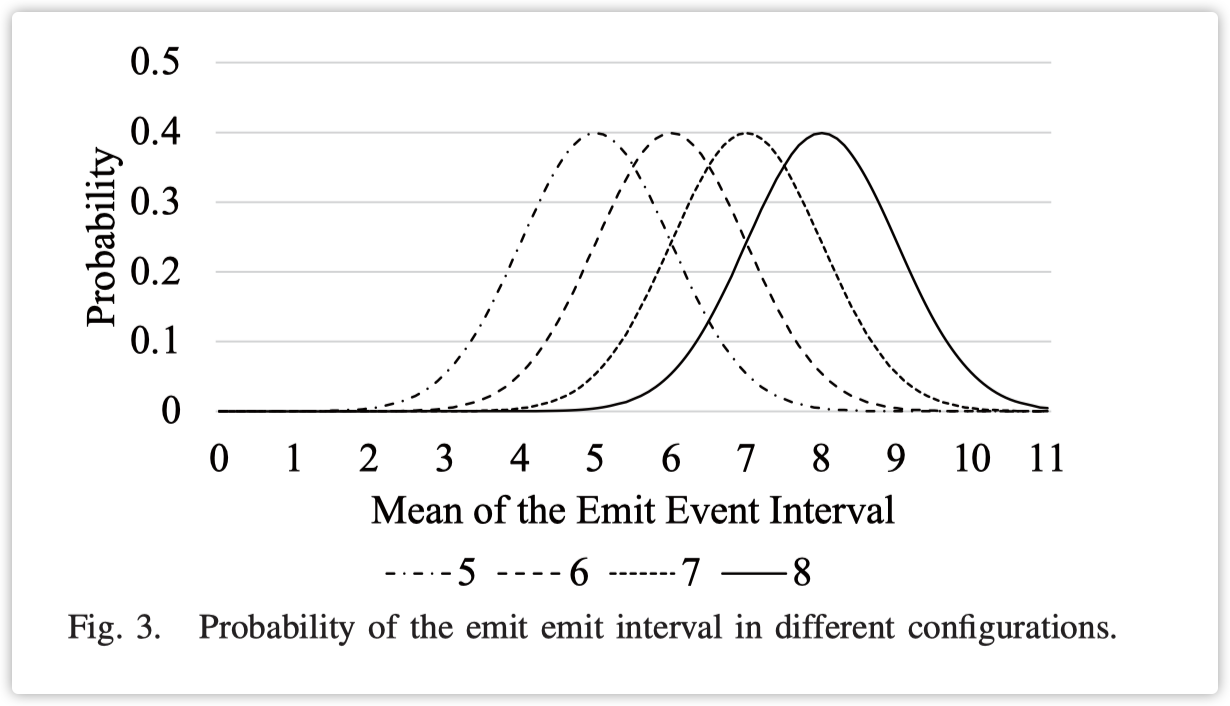
我们假设任务需要单独的设备。在本文中,我们使用传感器来生成任务。为了确保我们的模型在真实网络中的可行性,我们假设同时到达的一组任务是独立的,并符合正态分布。每个任务通过它需要处理的时钟周期数来评估任务的大小。由于本文描述的调度算法与任务的计算量无关,因此我们假设处理任务所需的时钟周期数是相同的。为了确保实验结果的稳定性,我们使用正态分布来控制任务生成的频率。图3显示了我们配置的任务概率。四条线是我们设置的四个正态分布的平均参数。横轴是下一个任务的计算延迟,纵轴是延迟的可能性。因此,平均值越小,处理的任务数量就越多。例如,当平均值为5时,最可能的情况是等待5个时钟周期来生成下一个任务。通过这个正态分布概率的约束,执行基准测试多次的过程中不会出现动态任务的生成和结果的大偏差。
每个任务都可以被抽象为由传感器发送,客户端确定在哪里执行它。然后,在计算器处进行计算。最后,处理过的数据返回给显示节点。完成这个任务循环的延迟代表了这个边缘云网络的性能。因此,任务循环可能在智能手机内部完成,也可能通过边缘节点完成,或者可能通过云完成。我们使用$D$来表示一个任务的总延迟,它由两部分构成:传输延迟$D_t$和计算延迟$D_c$,即$D = D_t + D_c$。在实际场景中,传输延迟是由传输介质和传输距离决定的。为了简化,本文假设$D_t$的传输延迟与节点跳数成正比。计算延迟是从任务开始到任务结束的时间间隔。这个时间间隔与完成任务所需的指令数$C_t$、节点的计算能力$C$以及节点上运行的任务数量$N$有关,即$D_c = N·C/C_t$。由于节点上运行的任务数量在任务计算过程中会发生变化,我们需要根据时间对这个值进行积分。在实验中,我们通过记录任务的完成状态来计算任务的计算延迟。
4. SCHEDULING STRATEGY
在本节中,我们介绍了一种基于主从模型的调度策略。如图2所示,主从模型明显降低了功耗,并且还能让更多设备能够被调度。低效的调度策略将导致边缘节点无法有效参与计算,并且会导致任务延迟的巨大增加。因此,我们策略的主要思想是尽可能触发从设备的睡眠模式,以减少边缘节点的功耗,并尽可能平衡负载资源以确保低延迟。

如算法1所示,我们使用$N_m$、$N_s$、$C_m$、$C_s$、$C_t$和$T$作为输入。$N_m$和$N_s$分别是主设备和从设备上运行的任务数量。$C_m$和$C_s$分别是主设备和从设备的计算能力。$C_t$是目标任务的MIPS。$T$是目标任务的最大容忍时间。此外,算法1中的其余主要符号都列在表I中。输出是任务的调度策略。我们首先考虑边缘节点的状态。如果边缘节点上运行的任务数量为$N_m = 0$,这意味着此时没有接收到任务。然后,我们将这个任务添加到主节点,并在第2到4行检查其可行性。我们计算任务的剩余计算延迟并将该值与最大容忍时间进行比较。如果没有超过,我们将任务发送到主节点。否则,我们在第5到7行计算将任务添加到从节点后是否超过了任务的最大容忍延迟。如果两个节点都不满足条件,任务将在第8行被发送到云端。如果在任务到达时边缘节点上运行的任务数量不为0,我们在第10行计算主从设备的相对空闲度$γ$。我们定义相对空闲度的值由主从设备的计算能力与运行任务数量的比例决定:$\gamma \leftarrow \frac{C_m \times N_s}{C_s \times N_m}$,$Cm越表示master的计算能力强度,Ns越大表示slave上运行的任务多,master上较为空闲,因此如果Cm与Ns越大,表明在master上计算效率更高,否则说明slave的计算效率更高。然后我们在第11到26行考虑相对空闲度来放置任务。如果该值不大于$γ ≤ 1$,这表明从设备此时相对空闲。我们优先将任务放在从设备上,计算剩余计算延迟,并在第12行将此值与最大容忍时间进行比较。如果没有超过,任务将在第14行发送到从设备。否则,我们在第15行计算主设备下的最大容忍延迟。同样,如果剩余计算延迟小于最大容忍延迟,我们在第17行将任务发送到主设备。否则,我们在第18行将任务上传到云端。如果值大于$γ ≥ 1$,我们在第19到26行改变计算顺序。我们首先在第20行计算主设备的剩余计算延迟。如果它没有超过最大容忍延迟,我们将任务发送到主设备在第22行。否则,我们在第25行对从设备进行相同的计算。如果以上都不满足,我们在第26行将任务发送到云端。

我们在算法1中使用的函数显示在第27到39行。我们在第31到39行计算将计划任务添加到设备后的任务延迟。我们首先在第32到33行将计算能力和计划任务所需的最大容忍延迟添加到设备上,并在第34行将运行任务的数量增加1。我们更新设备上任务的计算延迟$D_c[i]$,其中
$D_c[i]=\frac{C_r[i]·N_r}{C}$。然后,我们在第36行比较它们是否超过了它们的最大容忍延迟$T_r[i]$。如果任何任务超过了其最大容忍延迟,函数将返回false,这表明任务不能被添加到设备中。否则,函数返回true。我们使用两个函数在第27到30行封装主从设备各自的计算参数。
5. SIMULATION AND RESULTS
在本节中,我们在iFogSim模拟器平台上进行了实验。iFogSim是边缘计算领域中一个受欢迎的模拟器,它实现了边缘架构的许多特性,例如边缘网络结构、任务模块的放置以及任务系统。在我们的模拟中,我们实现了我们的调度策略,并基于iFogSim模拟器修改了电源消耗模型以适应休眠电源消耗模式。我们假设每个传感器都装备了一组用于接收任务的边缘节点。在我们的模拟中,使用了24个边缘节点,这些节点分为4组。模拟器的详细配置显示在表II中。对于每组,我们设置了六个通过网关和代理服务器连接到上级云的边缘节点。
我们首先在主从模式和非主从模式下执行了调度策略。实验结果显示在图4中。横坐标是体系结构中网关下的设备名称,纵坐标是本次实验中边缘节点的功率消耗。根据结果,我们发现功率消耗由于正态分布而有一定的波动,但平均值仍然非常稳定,这意味着每个节点的功率消耗相似。因此,我们得出边缘节点处理的任务总数相似,不受动态生成的影响。

如图5所示,我们实验了不同任务生成密度。横坐标是每个任务的正态分布中的均值,纵坐标是本次实验中边缘节点的总功耗。实验结果表明,均值为5时,非主从的功耗比主从低3.3%。在均值为7的实验中,功耗下降了18.5%。在均值为7的实验中,功耗下降了26.3%。在均值为8的实验中,功耗下降了27.9%。可以得出结论,随着任务生成的密集,主从模式下策略的优势越来越小。本文提出的算法在任务密度小的情况下对功耗优化明显。当任务密度大时,两种模式下的功耗几乎相同。如图6所示,我们计算了不同任务量下两种情况的延迟。横坐标是每个任务的正态分布中的均值,纵坐标是本次实验中所有任务延迟的平均值。实验结果表明,在均值为5的实验中,非主从的延迟比主从的延迟高出0.04%。在均值为6和7的实验中,延迟分别增加了5.25%和16.69%。同样,均值为8时,延迟增加了17.07%。本文提出的算法对延迟有一定的副作用,但在不同的实验组中,节能比例大于延迟增加比例。
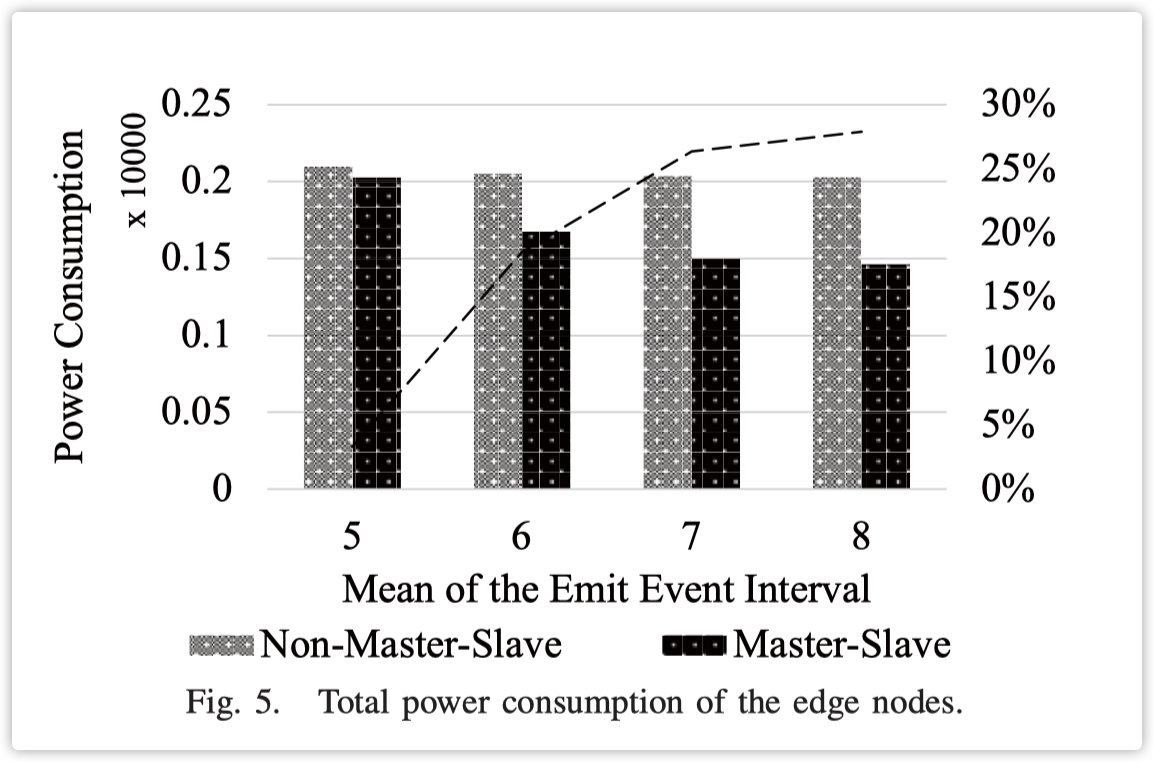
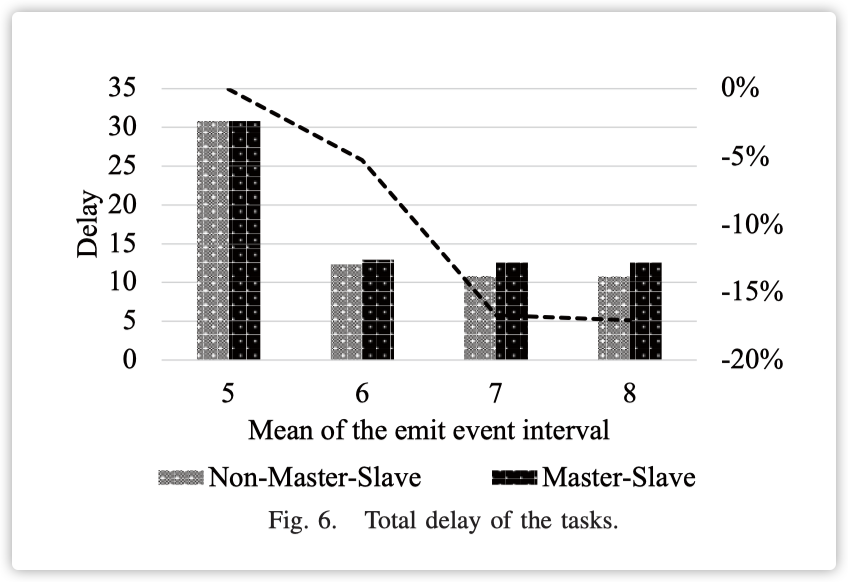
根据上述实验结果,我们做出以下推测。假设一个任务是最小的迁移单元,我们不能同时在两个设备上放置一个任务。由于任务是不可分割的,在主从模式和非主从模式的总计算能力相同的情况下。
- 当没有任务要处理时,我们可以看到主从模式下的功耗比非主从模式下的功耗低得多。
- 当只有一个任务要处理时,根据主从模式,从节点必须处于休眠模式。非主从模式下的计算能力明显强于主从模式。因此,在这种情况下延迟会有一定的增加。
- 当任务数量大于一个时,由于边缘节点的能力有限,这两种模式之间的性能差距并不明显。
6. CONCLUSION
在本文中,我们关注移动边缘计算中任务的功耗问题。我们的目标是在满足资源和延迟约束的同时,降低边缘节点供应商的功耗。我们首先引入了一种基于边缘节点睡眠状态的功耗模型。根据睡眠功耗模式的特点,我们将边缘节点分割为两个虚拟节点,即主节点和从节点。
然后,我们提出了一个有效的算法来调度这些节点以减少功耗。为了验证我们算法的有效性,我们使用iFogSim模拟器作为我们的实验平台。我们详细阐述了模拟器的线性功率模型和基于计算延迟和传输延迟的延迟模型,并提出了一个基于正态分布的任务生成模型。这个模型不仅确保了任务的动态生成,还实现了在一定时间内生成的任务总量的稳定性。实验结果表明,我们的算法显著优化了功耗,特别是在任务空闲时。在空闲任务的测试中,最高能耗比原算法低27.9%。
Comments 1 条评论