

为期四天四夜的美赛终于结束了,在这个过程中有许多感悟,如果不记录一下可能就有点可惜了。
赛前准备
在比赛之前,也就是寒假这个时间节点,我基本都在学习模型、实现模型和描述模型,这三个点应该是建模竞赛里面最重要的三个部分,希望能尽量减少比赛过程中的容错率。除了控制与优化这类模型我没有准备之外,每一种类别的模型我大概都准备了一到两个,比如数据处理,我准备了插值、拟合、和主成分;关联与因果模型我准备了皮尔逊相关系数、斯皮尔曼相关系数和典型相关分析 ;分类与判别我准备了K-means++、系统聚类和分类算法 (woc,现在写总结的时候突然想到或许可以将分类模型用在c问,构建01回归来判断...) ;评价与决策类模型主要准备的是:层次分析、topsis以及用熵权法修正topsis;当然还有最重要的预测模型:多元回归、灰色预测(因为这个模型是中国人提出来的,好像美赛不推荐用)还有最不容易理解的时间序列预测。
准备上面的这些模型几乎用了我一个半月的时间,当然,这么短的时间之内,把每个模型里面的原理都搞通搞懂显然是不太可能的,只能尽可能的理解,然后每个模型记一两道例题,这样就知道什么模型能用于什么问题了(这个非常重要),学习模型最重要的就是直到怎么运用到实际的题目里面去,剩下的,就交给写作的人吧。
队伍组成
由于我们队伍中的三个成员都是cs专业的,所以在知识的储备这方面并没有什么优势,我主要负责的是数据处理、模型建立和模型实现,两外两位同学分别负责文章和两边辅助。一般的队伍配置好像都是建模、编程和写作,但我觉得其实建模和编程可以让一个同学来完成,这样第三位同学就有了更多的选择,比如可以像我们这样两边辅助的,也比如可以选择增加一位对统计比较了解的同学。理想的组合应该是:建模的同学能建出解决问题的模型并且是可实现的,写文章的同学负责论文构建,排版美化,和文献索引,为模型提供有力的材料支撑。这两位同学的压力都是非常大的,建模的同学决定了成果的下限,而写作的同学决定了文章的上限。
什么样的同学适合建模?首先肯定是想法要多,然后把什么模型用于什么问题了解清楚,起码等懂一点代码。比赛的时间非常紧迫的,代码这方面完全自己写也不太现实,可以用提前准备好的,也可以利用网络搜索。
什么样的同学适合写作?首先肯定是需要积累的, 前期大量阅优秀论文,知道每个部分应该怎么写,比如摘要怎么写,模型的优缺点、灵敏度分析这些套路都搞清楚,就像我们考四六级背过的模板一样,你平时不积累,到关键时候肯定写不出东西来。再就是要有节奏,比如:在拿到题目后,你需要搞清楚问题在问什么,将背景和问题的重述之类的写完。在前期的讨论中,你需要将建模手的思路搞的清清楚楚,然后去搜索相关材料作为支撑。再就是可以学习一下怎么排版,比如Latex肯定比word要高级,但排版所需要的时间肯定也更长。
比赛的过程
3月6日
由于是第一次比赛,而且是线上建模,所以比较激动,5.40多就起床跑到官网上去下载题目,下载速度巨慢,十几兆的文件居然下了10分钟左右。由于第二周只有BCF,B题工科背景很强、F题语文建模玩不来,所以我们主要冲着C题去的。拿到题目后我先看的是B题,大意是构建最稳定的沙堡,看了一眼就知道高中物理只有十几分的我肯定玩不来,F题看都没看就去看C题了。题目大意是亚马逊上有个阳光公司,他们家主要卖奶嘴、吹风机和微波炉,然后每个商品有对应的销售记录,你需要根据它们的销售记录回答问题。
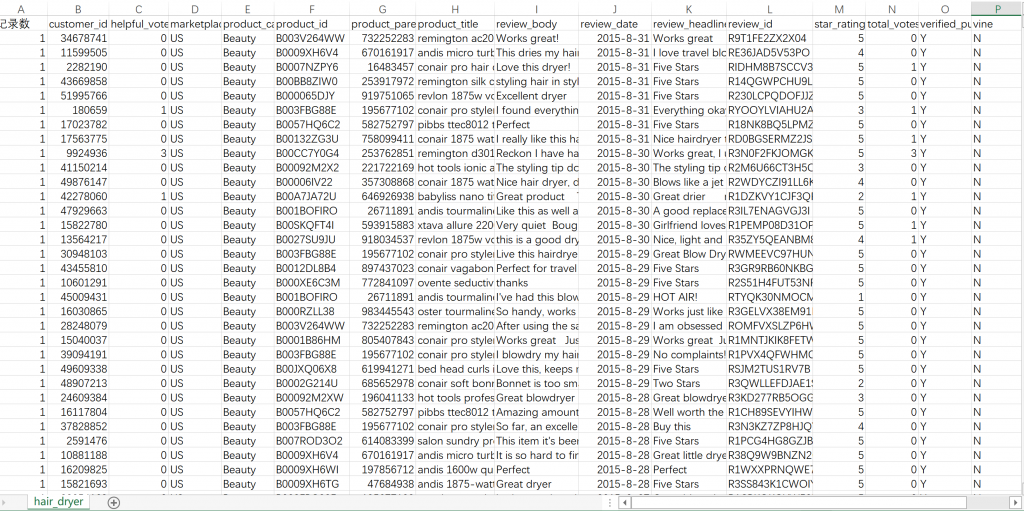
首先看到数据是炫酷的tsv格式,看到数据格式就已经有一点点郁闷了,于是去了解了一下,转换成了csv格式,就可以用excel打开了。格式调好之后看到一共大概40000多*15个元素,而且评论里面有很多emoji(在excel中打开就是乱码)和html的标签,更加郁闷了。读完题后发现我们需要将评论文本,也就是上图中的review_body和review_hedline这种文本,根据感情倾向转换成定量的数据。看到这里彻底郁闷了,突然想到之前看过学长写过的博客,里面有讲到如何对文本情感分析,也就是需要用到自然语言处理(NLP)的知识。但是就我的经验来看,我们要在这么短的时间内学习并实现肯定是不可能的,所以我就想看看有没有什么包、什么库可以调用。
所以我们第一天的工作基本就是对数据进行清洗和情感文本分析。数据清洗我是用的是tableau里面的筛选功能(在建模前五天我基本都在学怎么用excel和tableau),清洗主要包括:评论里面用了符号的、未购买但评论了的用户(保留vine,这个有用)和不属于那一类别的商品,比如microwave,我们挑选出product_tittle那一列不包含microwave的进行排除。因为对这些功能都不是很熟练,所以这个工作大概做了一上午。
清洗完成后就开始学怎么进行文本情感分析,主要是情感文本分析要用到python,我们队虽然都是cs专业的,但用python的场景特别少,我还是去年六月份左右看的python的基本语法,到现在只能记得一点点python的语法。我们最开始找到的是SnowNlp这个包,这个包可以分析中文的情感倾向,既然中文有的话,英文那就更别谈了,所以我们又找找找。发现了textblob这个包可以分析英语,将文本数据化到-1和1之间,比如-1就是消极,1就是积极。我用它做了几个简单的分析,像good之类的词都可以很好的试别,但我试了一下出现频率最高的five stars,它给我们的结果为0,所以在准确度上确实有点堪忧,但我们也没有更好的办法了,就将就了一下。最后导出的时候,我将[-1, 1]这个区间映射到了[1, 5]上,这样就相当于统一了和评星之间的单位,由于在这个过程中发生了许许多多的意外,比如导入数据导出数据啥的,所以大概到吃完饭的时间才弄完。
晚上我们主要是分析的是第一问,第一问说的很笼统

我们在定量和定性之间纠结了很久,如果第一问就用定量的话,第二问和第一问就会有很多重复,所以我们就相当于队数据做了一个描述性统计。使用excel里面的数据透视表(这个功能不了解的同学,建议好好学习一下,太强了)对每个评星进行统计,就类似一星有多少客户、二星多少.......另外,我们还分析了vine这个群体和普通用户这两个群体之间的平均help_vote,得出vine群体高于普通用户(最后在写信的时候可以说一下重视培养vine)。
3月7日
由于考虑到后面的几个问题都和review有关,而textblob的准确率又不高,所以我们还是想自己搞一搞(好吧还是naive了,啥基础都没有怎么可能搞的出来),这个花了我们很长时间,在这个过程中还尝试了mathematical、在线统计之类的软件,都不太理想。
几乎一整天都在考虑情感分析,然后通过肉眼观察评论中什么词出现的频率最高,做了词云图,效果如下:

由于还是情感分析这块我们还是出现了很多问题,所以在最后我们还是用的textblob得出来的结果进行计算。晚上差不多就开始考虑第a问和b问,在a问中,我们选取了star、review_body和review_headline这三个指标,用层次分析和熵权法给指标赋权重,然后就过了。b问我们当时想的是直接用a问得出的结论,进行计算得分、然后根据这个得分画折线图来分析趋势,或者用拟合来对未来进行预测,都得到了结论,但感觉都不恰当。
这天走的弯路最多,浪费了很多的时间
3月8日
这天主要讨论的是c问,d问和e问,让我们最棘手的是c。

按我们的观点来的话,我们肯定是需要找一个指标来判定这个产品是成功还是失败,那就和a问一样了,就多了一个潜在的成功或失败。我们很难找出一个度量来描述这个成功或失败。最后,我们还是考虑使用回归来分析,将一段时间内的评价量作为因变量( 因为评价量可求 ),和销量挂钩,然后将star、body和headline作为自变量来进行回归分析,可以说是在瞎搞了。。但是确实也是没有办法了,star、body和headline,只要是个正常人都知道它们之间肯定是相关的,如果相关的话,就得考虑完全多重共线性的影响(就类似如果一个向量小组里面,一个向量能够被其他向量线性表示的话,那这个向量是垃圾向量,在里面充数的,向量小组线性就相关,由于回归用的是最小二乘,在计算结果的时候,矩阵不可逆,就几乎得不到正确的结果),其实当时我还考虑了能不能有主成分操作一下,解决完全多重共线性的影响,但由于我们当时时间已经不多了,就没有考虑。当然还有一个问题就是,就算得到了回归方程,我们应该如何用这个回归方程来预测商品是否会成功或失败?(如果有大佬在这方面有所了解的话,希望能多给给小弟一些建议)我们是分析趋势得到的结论(肯定是不对的,实在是没办法了,太菜了)。
c题随便就过了之后,又开始纠结d题,中间也出现了分歧,我就直接说我们最后的方法把,最后是用tableau导出一段时间(应该是按季度导出的)的平均评星和评价量。然后分析拐点,记录一下拐点附近的评星,然后记录对应的后一季度的评价量,用这两个条件来进行相关性分析,用的是斯皮尔曼相关系数。
e题,郁闷。因为又要用到自然语言处理的知识,于是就又找找找,然后就被我们找到了怎么进行分词统计,在python中主要用split函数来操作......不得不说我们队信息搜集能力是真的强。然后就是将评星分类,一星的一类,二星的一类、三星的一类......然后分析每一类星星中最高的是那个。就用这两个指标来算相关性,还是用的斯皮尔曼相关系数。
3月9日
已经是最后一天了,而我们的而论文还有很多东西没有写,有点急,这里要批评一下负责写作的阿泽。然后我们在进行复盘的时候,发现我们可能是对于b题有所疏忽了,题目问的是基于时间的度量和模式,我们就简单的考虑成基于时间的趋势了。所以就又重新开始建立时间序列模型,给奶嘴建一个、吹风机建一个、微波炉建一个,具体是啥我忘了,建了一个简单季节性、两个SARIMA模型。
然后就开始赶论文了,其实我是不打算动笔写的(建模太累了,想偷懒)。。。然后发现我们论文的主体部分还没有写,就是最重要的:模型原理,模型建立,模型求解。好吧,由于我之间做过写作练习,速度会比其他队友快一点,而且模型是我建的,我对这些模型也很熟悉,所以这个工作就由我来做了(吐槽:工作量真大)。
后面又有很多意外,比如latex出的bug之类的,调了好几个小时。。。当时还以为我们的论文交不了了,所以最终的论文真的很惨,机翻一遍之后我们也没有读,有些图片也没有插。
大概到10号的8点多,我们的论文才算全部弄完,而且什么灵敏度分析啥的还没写,而且本身三个人也累了,都几乎25个小时没睡觉,所以就交了。
总结
由于我和写作的同学都没有参赛经验,配合比较差,对于比赛的节奏也没有一个清晰的认识,所以算是一次失败的建模吧。当然,第一次的结果也那么重要(疯狂自我安慰...)。在这四天里面,高强度的学习、思考和实践,一次次的出错,一次次的解决,对许多模型也有了更进一步的理解,也大概知道了自己未来可能会走什么方向,这或许才是最大的收获吧。
马上又有很多比赛要来了,但我觉得,那些比赛都不如数模锻炼人,大概率我在今后的学习中只要有机会就会去参加,也希望自己能在这方面有所成就。
最后吐槽一下指导老师有什么用啊。。。
传送门: http://www.wulnut.top/2020/03/10/%E7%AC%AC%E4%B8%80%E6%AC%A1/ 另一位队友写的😄
Comments 2 条评论
“就算得到了回归方程,我们应该如何用这个回归方程来预测商品是否会成功或失败?”
这个问题其实可以看成二分类问题,用逻辑回归就行
训练数据可以手动找一些明显成功了的品牌(比方说销量特别多,评分特别好)
测试数据就是剩下的品牌
@mathor 哇,学习了,学长牛啊👍