

step1 Java与Scala
安装Java,在mac上安装Java非常简单,直接安装zulu的包即可:链接,版本一定要装Java8的,我之前装了个17的版本,后面一堆问题,很麻烦。下载完dmg包之后直接安装就行了,然后配置环境变量:
vim ~/.bash_profile
然后加入两行:
export PATH=$PATH:/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home
export PATH=$PATH:"$(/usr/libexec/java_home -v 1.8)"安装scala ,使用homebrew来安装,如果没有homebrew就先去安装下,也很简单:brew install scala
然后同样配置环境变量:(根据你自己的homebrew安装目录来)
export PATH=$PATH:/opt/homebrew/Cellar/scala/2.13.8/bin
step2 Hadoop
使用homebrew安装hadoop。直接brew install hadoop,然后就可以了。装完后测试下是否成功,运行hadoop version
然后需要配置四个文件,分别是hadoop-env.sh, core-site.xml, mapred-site.xml,hdfs-site.xml和yarn-site.xml
在如下路径:
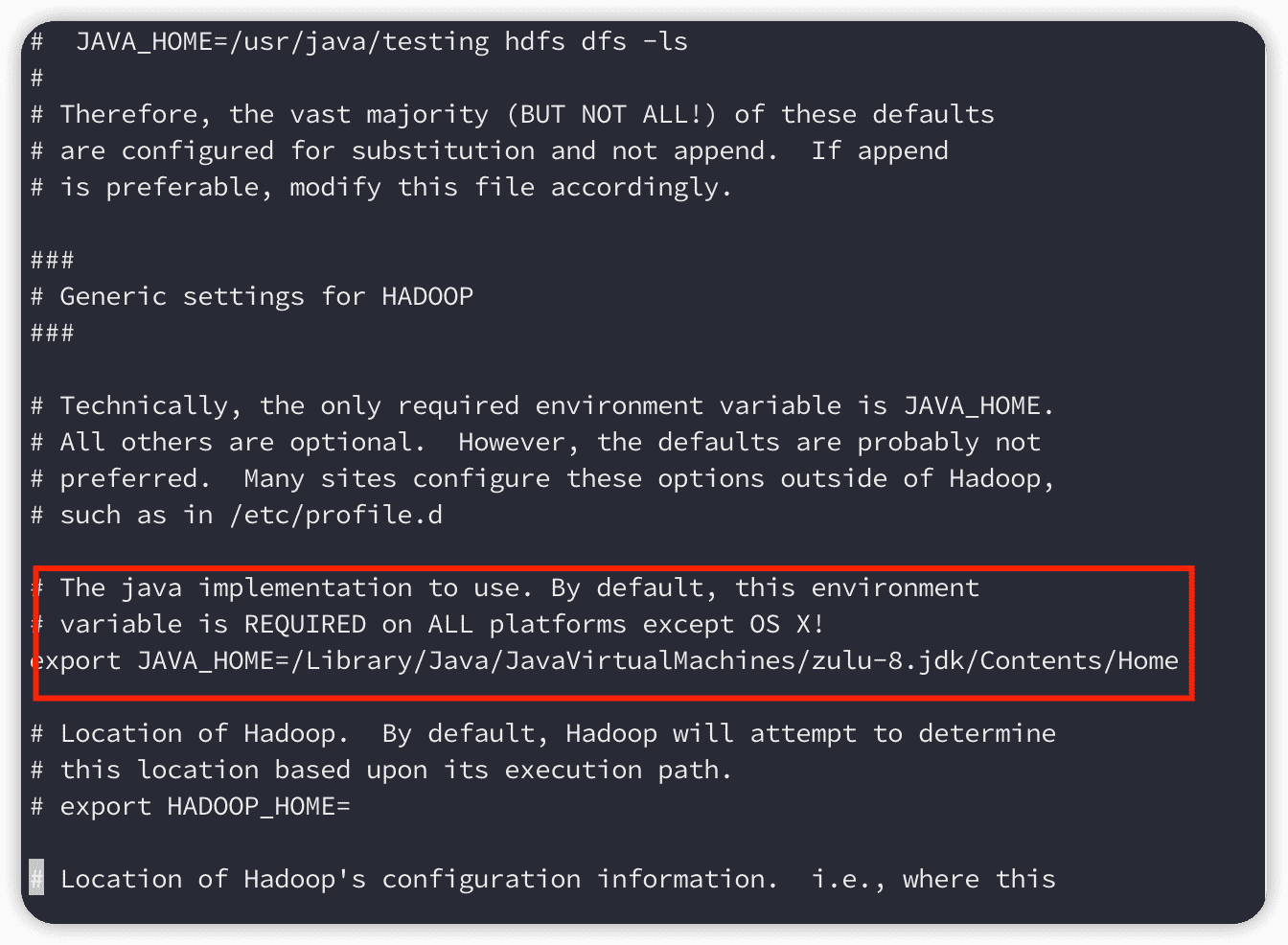
- 首先在hadoop_env.sh文件中,我们需要去掉java环境变量注,如果配置的不对,改成你电脑上的目录:
- 关于jdk的路径:
/usr/libexec/java_home -V运行这个就可以知道了
- 然后配置
core-site.xml文件,第一个配置指定的是hdfs文件系统的域名:端口,后面如果要上传文件或者获取文件会用到这个,第二个是设置一个临时存放数据的文件夹,需要根据你自己电脑上hadoop的路径来
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/homebrew/Cellar/hadoop/3.3.1/tmp</value>
</property>
</configuration>- 配置
mapred-site.xml(如果你的目录下没有这个,而是.template后缀的文件的话,可以直接将复制一份,并且将名字改成mapred-site.xml),这个文件是配置mapreduce的参数,用yarn来进行调度(好像是这样qaq)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>- 配置
hdfs-site.xml,dfs.replication指定了每个HDFS数据库的复制次数,通常为3,而我们要在本机建立一个伪分布式的DataNode所以这个值改成了1,dfs.permissions表示关闭防火墙,然后后面两个配置表示把路径配置成本地的,作数据冗余
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/homebrew/Cellar/hadoop/3.3.1/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/homebrew/Cellar/hadoop/3.3.1/data1</value>
</property>- 配置
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:8888</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>至此,hadoop的配置就完成了,下面我们需要打开mac的远程连接功能
Step3
找到设置里面的共享,然后设置运行远程登录
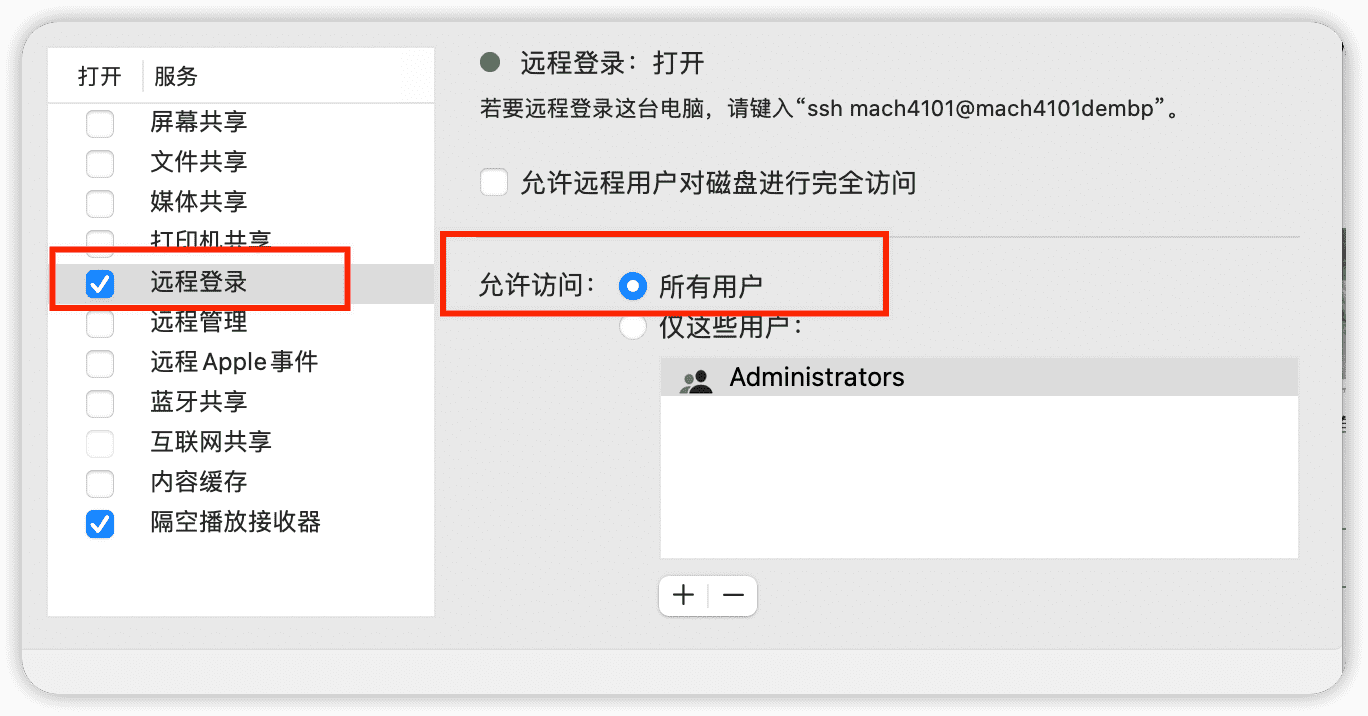
然后试试ssh localhost,应该就可以连接了,但是有一个不好就是需要输入密码:
ssh-keygen -t rsa
[按回车就完事]
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keysstep4 启动hadoop
然后就可以启动传说中的(伪)分布式文件系统了:
首先格式化文件系统:hadoop namenode -format(这个只需要最开始创建的启动一次就行了,因为我已经格式化过了,所以没有格式化的图)
然后进入到sbin目录:
然后运行start-dfs.sh和start-yarn.sh,(如果要关闭就是stop-xxx.sh)
使用jps查看当前的hadoop运行情况,都启动了就没什么问题
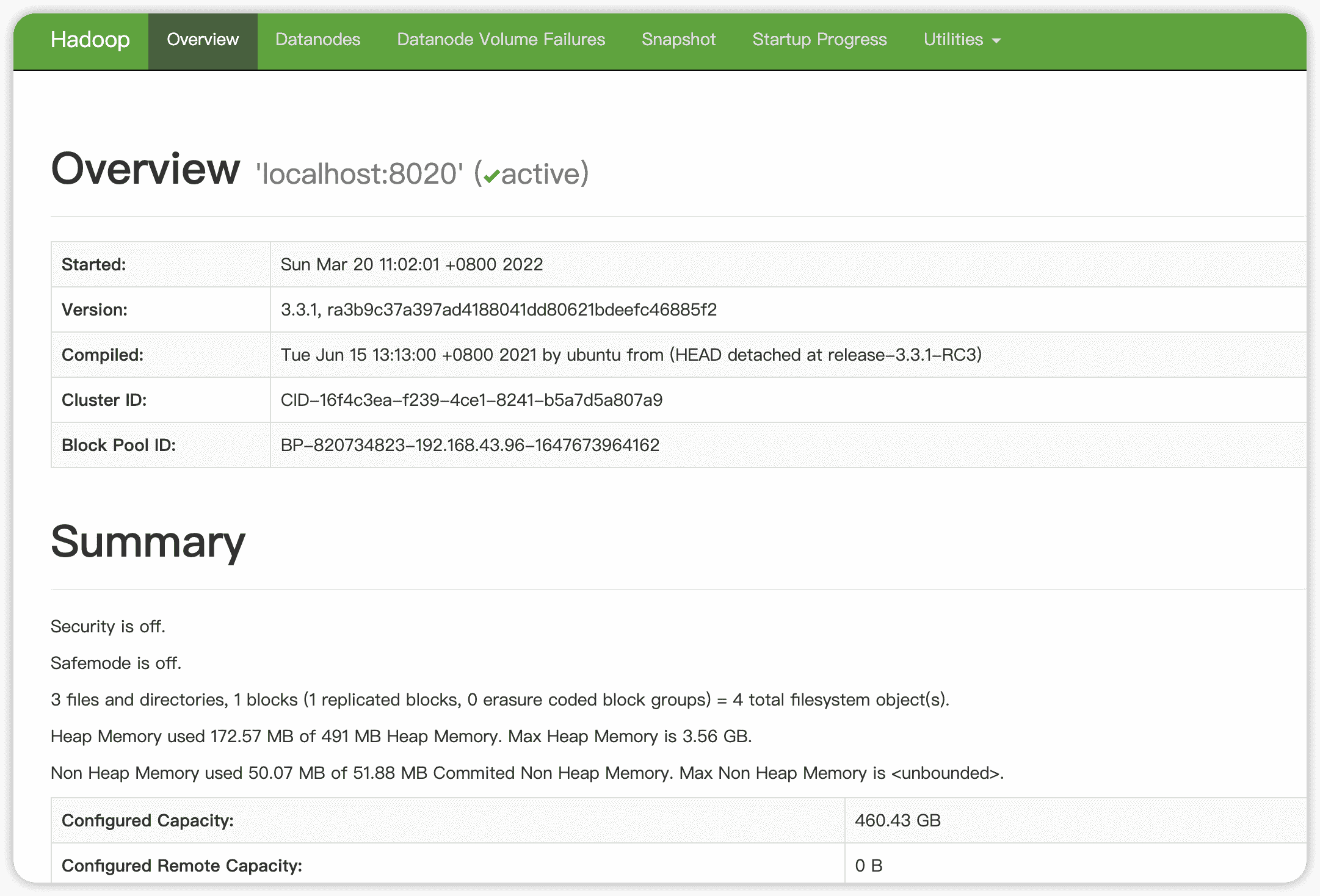
然后去webui界面看看:
http://localhost:9870
看看yarn:http://localhost:8088

这样的话,就成功了,我们可以使用一些命令行来操作hadoop文件了
hadoop fs -ls / 查看根目录下的文件及文件夹
hadoop fs -mkdir /test 在根目录下创建一个文件夹 testdata
hadoop fs -rm /.../... 移除某个文件
hadoop fs -rmr /... 移除某个空的文件夹step5 安装maven
直接brew install maven即可,如果有需要可以配置下本地仓库的路径,我懒得改qaq
step6 安装spark
brew intall apache-spark然后安装就完了,我在安装的时候遇到了一个问题,就是安装依赖包的时候出错,解决的办法就是直接brew install 依赖包,然后再brew install apache-spark就可以了
然后进入/opt/homebrew/Cellar/apache-spark/3.2.1/bin

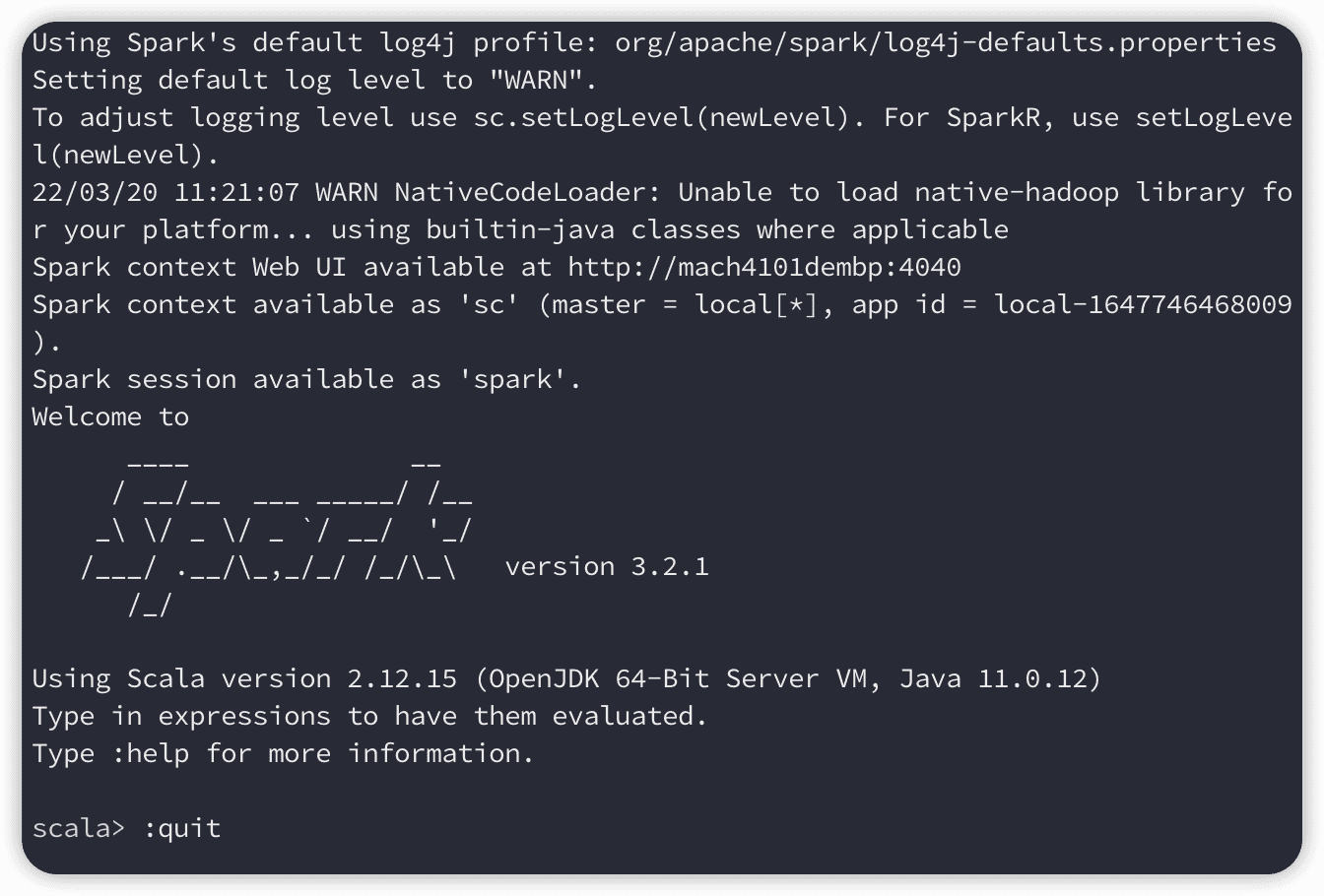
然后运行./spark-shell试试:
如果出现下图这样的就表示成功:并且可以通过:http://mach4101dembp:4040来打开webui
step7 测试spark与hadoop
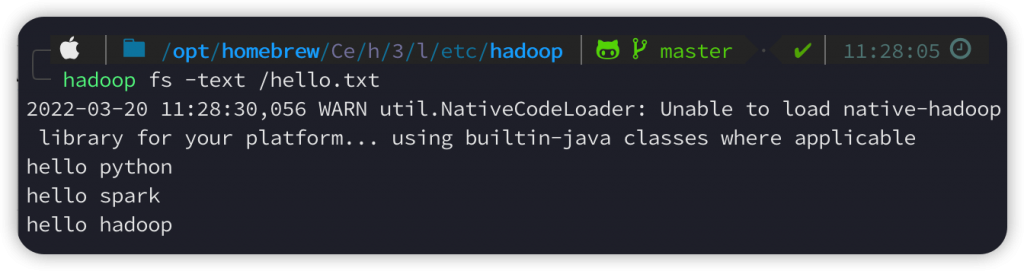
我在hadoop的根目录下放了一个hello.txt文件,这个文件的内容如下,由三行文字组成:
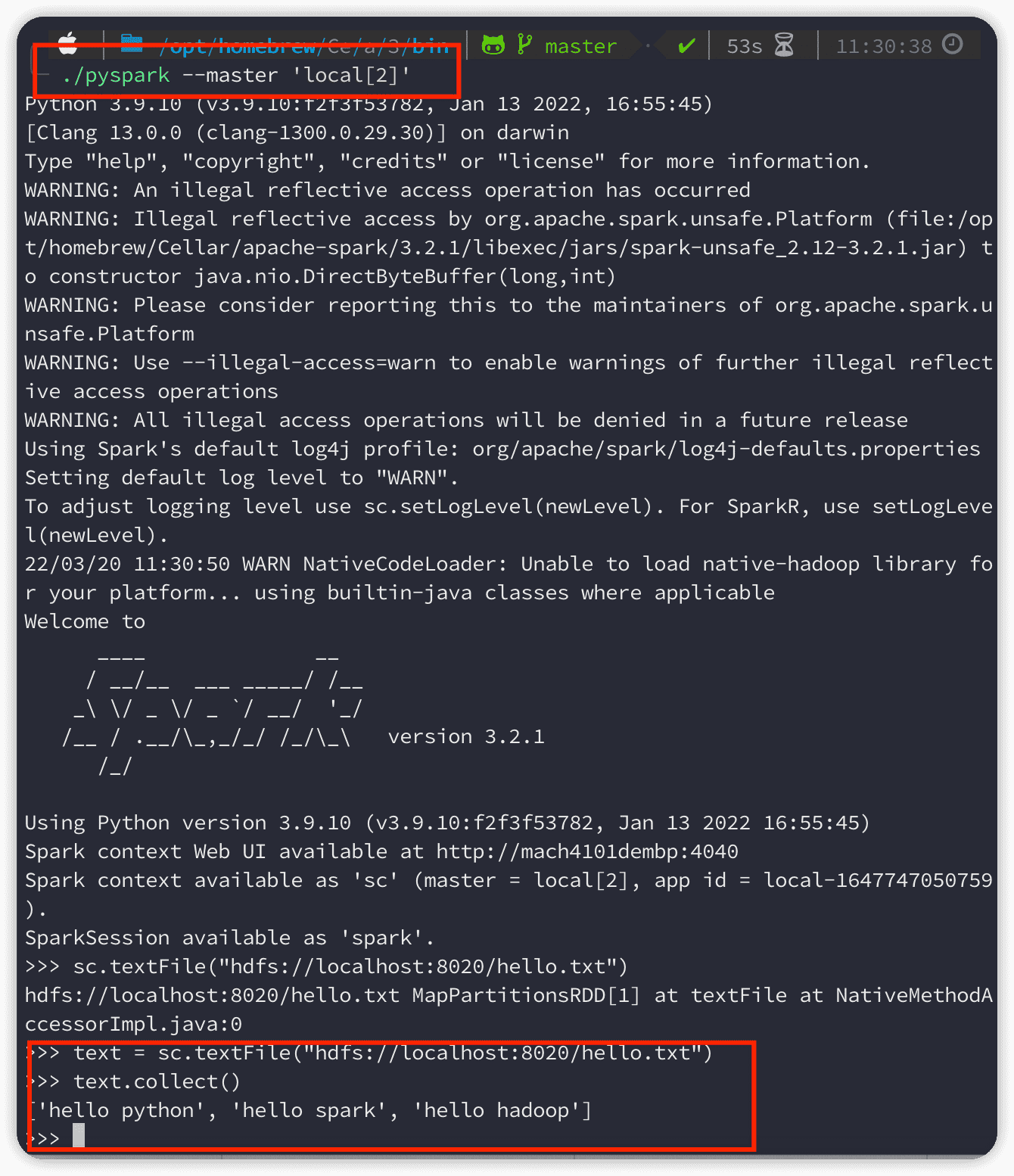
在spark的bin目录下,使用./pyspark --master 'local[2]'来运行,local表示运行在本地,2表示两个线程:
Finished
Ok,以上就是本篇博客的全部内容了,装hadoop和spark花了我很长的时间,因为其中的坑实在是太多了,比如Java版本、比如hadoop webui的端口由以前的50070改成了9870之类的,如果您在安装过程中出现了什么问题,也可以在本篇博客的评论区留言,最后,也感谢您阅读到这里!
Comments NOTHING